
[ad_1]
Graph transformers are a kind of equipment learning algorithm that operates on graph-structured knowledge. Graphs are mathematical constructions composed of nodes and edges, where nodes represent entities and edges depict relationships between all those entities.
Graph transformers are utilised in a variety of purposes, like normal language processing, social community examination, and pc eyesight. They are normally employed for node classification, backlink prediction, and graph clustering duties.
Just one preferred type of graph transformer is the Graph Convolutional Community (GCN), which applies convolutional filters to a graph to extract characteristics from nodes and edges. Other varieties of graph transformers involve Graph Attention Networks (GATs), Graph Isomorphism Networks (GINs), and Graph Neural Networks (GNNs).
Graph transformers have proven great promise in machine discovering, specifically for graph-structured data duties.
Graph transformers have proven promise in different graph understanding and illustration jobs. Nevertheless, scaling them to larger graphs when preserving competitive accuracy with concept-passing networks continues to be demanding. To handle this situation, a new framework known as EXPHORMER has been released by a team of scientists from the College of British Columbia, Google Investigate and the Alberta Equipment Intelligence Institute. This framework utilizes a sparse focus system based on digital world nodes and expander graphs, which have appealing mathematical features these types of as spectral expansion, sparsity, and pseudorandomness. As a final result, EXPHORMER allows the developing of strong and scalable graph transformers with complexity linear to the dimension of the graph though also delivering theoretical qualities of the ensuing types. Incorporating EXPHORMER into GraphGPS yields versions with competitive empirical success on various graph datasets, which includes a few point out-of-the-artwork datasets. Furthermore, EXPHORMER can manage larger sized graphs than former graph transformer architectures.
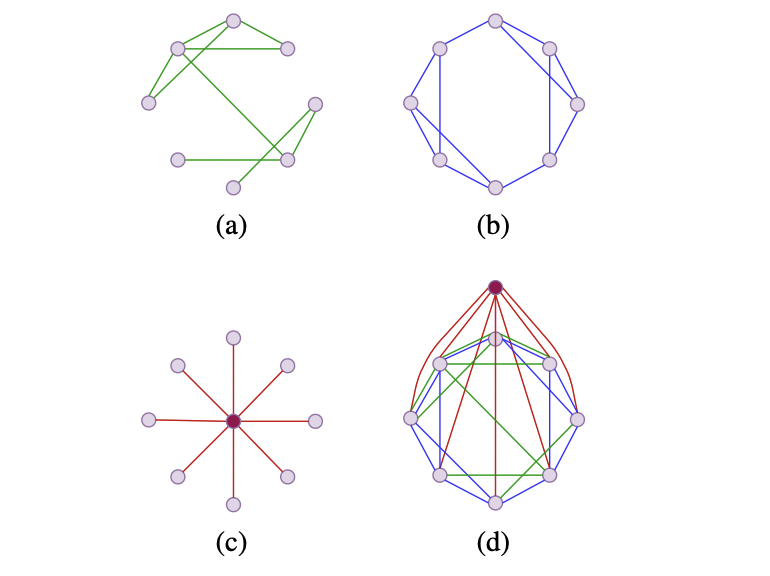
Exphormer is a strategy that applies an expander-dependent sparse attention mechanism to Graph Transformers (GTs). It constructs an conversation graph making use of a few principal parts: Expander graph notice, World-wide awareness, and Regional neighborhood notice. The Expander graph attention lets information propagation amongst nodes without having connecting all pairs of nodes. International interest provides virtual nodes to generate a world wide “storage sink” and delivers universal approximator functions for complete transformers. Nearby community focus models neighborhood interactions to get info about connectivity.
Their empirical study evaluated the Exphormer approach on graph and node prediction responsibilities. The crew found that Exphormer put together with information-passing neural networks (MPNN) in the GraphGPS framework obtained point out-of-the-artwork results on quite a few benchmark datasets. Inspite of getting much less parameters, it surpassed all sparse awareness mechanisms and remained competitive with dense transformers.
The team’s main contributions involve proposing sparse focus mechanisms with linear computational costs in the amount of nodes and edges, introducing Exphormer, which brings together two approaches for developing sparse overlay graphs and introducing expander graphs as a strong primitive in developing scalable graph transformer architectures. They have been capable to reveal that Exphormer, which combines expander graphs with world-wide nodes and nearby neighborhoods, spectrally approximates the whole consideration mechanism with only a modest amount of layers and has universal approximation attributes. The proposed Exphormer is primarily based on and inherits the attractive houses of the GraphGPS modular framework, a lately introduced framework for making general, consequential, and scalable graph transformers with linear complexity. GraphGPS brings together common nearby message passing and a international attention mechanism, allowing sparse interest mechanisms to make improvements to performance and decrease computation costs.
Look at out the Paper and Github. All Credit For This Investigate Goes To the Scientists on This Venture. Also, don’t overlook to join our 16k+ ML SubReddit, Discord Channel, and Email E-newsletter, in which we share the latest AI analysis news, neat AI tasks, and far more.

Niharika is a Specialized consulting intern at Marktechpost. She is a 3rd 12 months undergraduate, presently pursuing her B.Tech from Indian Institute of Engineering(IIT), Kharagpur. She is a very enthusiastic particular person with a keen desire in Device learning, Details science and AI and an avid reader of the most recent developments in these fields.
[ad_2]
Resource website link