
[ad_1]
Code-improve critiques are a vital aspect of the application growth method at scale, using a substantial amount of money of the code authors’ and the code reviewers’ time. As component of this system, the reviewer inspects the proposed code and asks the author for code changes by means of comments published in normal language. At Google, we see hundreds of thousands of reviewer responses for every year, and authors call for an common of ~60 minutes active shepherding time in between sending modifications for overview and last but not least submitting the modify. In our measurements, the expected active function time that the code author will have to do to tackle reviewer reviews grows virtually linearly with the quantity of remarks. Having said that, with equipment studying (ML), we have an chance to automate and streamline the code critique system, e.g., by proposing code changes primarily based on a comment’s textual content.
These days, we explain applying modern advancements of substantial sequence types in a actual-environment setting to routinely take care of code review reviews in the day-to-working day enhancement workflow at Google (publication forthcoming). As of today, code-alter authors at Google tackle a significant total of reviewer feedback by applying an ML-suggested edit. We assume that to minimize time spent on code reviews by hundreds of countless numbers of hrs each year at Google scale. Unsolicited, quite constructive suggestions highlights that the effects of ML-proposed code edits raises Googlers’ productiveness and enables them to focus on extra imaginative and advanced jobs.
Predicting the code edit
We started off by coaching a model that predicts code edits wanted to tackle reviewer feedback. The design is pre-properly trained on several coding responsibilities and related developer routines (e.g., renaming a variable, restoring a damaged establish, modifying a file). It is then fantastic-tuned for this distinct process with reviewed code adjustments, the reviewer reviews, and the edits the creator carried out to address those people responses.
 |
| An case in point of an ML-proposed edit of refactorings that are distribute within just the code. |
Google utilizes a monorepo, a solitary repository for all of its software artifacts, which will allow our coaching dataset to include all unrestricted code applied to construct Google’s most new application, as well as earlier versions.
To increase the model quality, we iterated on the instruction dataset. For example, we as opposed the design overall performance for datasets with a solitary reviewer comment for every file to datasets with several comments for every file, and experimented with classifiers to clean up up the schooling knowledge primarily based on a modest, curated dataset to opt for the model with the most effective offline precision and recall metrics.
Serving infrastructure and person knowledge
We built and executed the characteristic on leading of the trained design, focusing on the general person experience and developer effectiveness. As component of this, we explored various user practical experience (UX) solutions by means of a sequence of user research. We then refined the aspect based mostly on insights from an inner beta (i.e., a examination of the element in progress) which includes user feedback (e.g., a “Was this valuable?” button subsequent to the proposed edit).
The ultimate product was calibrated for a goal precision of 50%. That is, we tuned the product and the strategies filtering, so that 50% of instructed edits on our analysis dataset are right. In basic, rising the focus on precision lowers the quantity of demonstrated prompt edits, and lowering the focus on precision sales opportunities to additional incorrect recommended edits. Incorrect suggested edits acquire the builders time and lower the developers’ have confidence in in the characteristic. We observed that a focus on precision of 50% provides a excellent harmony.
At a large stage, for every new reviewer remark, we produce the design input in the identical format that is applied for training, query the product, and create the proposed code edit. If the product is assured in the prediction and a several more heuristics are happy, we send out the prompt edit to downstream devices. The downstream devices, i.e., the code overview frontend and the built-in improvement environment (IDE), expose the recommended edits to the user and log consumer interactions, these types of as preview and apply occasions. A committed pipeline collects these logs and generates aggregate insights, e.g., the total acceptance prices as reported in this blog post.
 |
| Architecture of the ML-prompt edits infrastructure. We course of action code and infrastructure from many products and services, get the model predictions and floor the predictions in the code overview instrument and IDE. |
The developer interacts with the ML-proposed edits in the code critique instrument and the IDE. Centered on insights from the user studies, the integration into the code evaluation tool is most appropriate for a streamlined evaluation experience. The IDE integration provides further functionality and supports 3-way merging of the ML-instructed edits (remaining in the determine below) in scenario of conflicting community adjustments on leading of the reviewed code condition (correct) into the merge final result (middle).
.gif) |
| 3-way-merge UX in IDE. |
Benefits
Offline evaluations point out that the model addresses 52% of opinions with a target precision of 50%. The on-line metrics of the beta and the entire interior launch confirm these offline metrics, i.e., we see design suggestions above our focus on design self esteem for around 50% of all related reviewer feedback. 40% to 50% of all previewed prompt edits are utilized by code authors.
We employed the “not helpful” comments through the beta to discover recurring failure styles of the product. We carried out serving-time heuristics to filter these and, therefore, reduce the quantity of demonstrated incorrect predictions. With these modifications, we traded quantity for top quality and noticed an greater authentic-environment acceptance fee.
.gif) |
| Code assessment tool UX. The recommendation is shown as aspect of the comment and can be previewed, used and rated as valuable or not valuable. |
Our beta launch confirmed a discoverability challenge: code authors only previewed ~20% of all generated proposed edits. We modified the UX and introduced a outstanding “Show ML-edit” button (see the determine over) next to the reviewer comment, top to an general preview amount of ~40% at start. We on top of that located that advised edits in the code evaluate software are normally not relevant because of to conflicting improvements that the creator did all through the evaluate method. We tackled this with a button in the code overview instrument that opens the IDE in a merge see for the advised edit. We now observe that extra than 70% of these are used in the code critique software and much less than 30% are used in the IDE. All these changes allowed us to enhance the total fraction of reviewer remarks that are resolved with an ML-recommended edit by a issue of 2 from beta to the total internal start. At Google scale, these success assistance automate the resolution of hundreds of countless numbers of remarks each individual year.
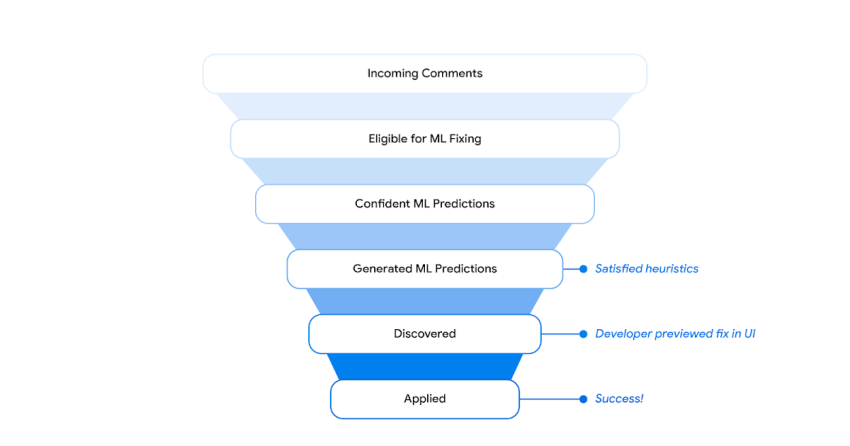
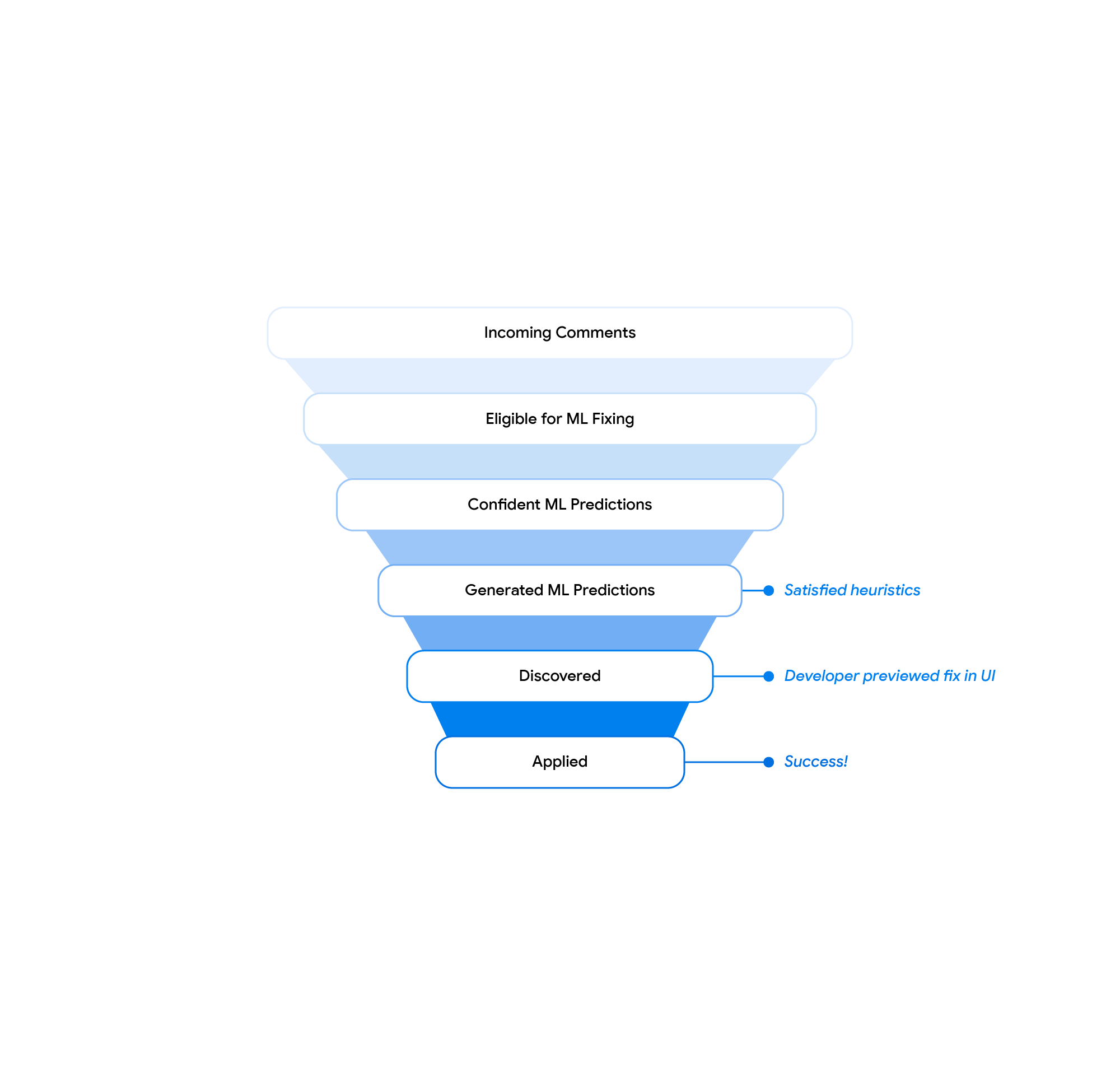
 |
| Strategies filtering funnel. |
We see ML-instructed edits addressing a broad variety of reviewer opinions in generation. This consists of simple localized refactorings and refactorings that are spread within the code, as shown in the examples all over the web site post earlier mentioned. The attribute addresses lengthier and less formally-worded remarks that need code generation, refactorings and imports.
 |
| Instance of a recommendation for a for a longer period and fewer formally worded comment that involves code generation, refactorings and imports. |
The product can also answer to complicated opinions and develop extensive code edits (proven below). The generated examination situation follows the existing device test sample, when shifting the specifics as described in the comment. Additionally, the edit suggests a extensive name for the exam reflecting the exam semantics.
 |
| Illustration of the model’s skill to answer to complicated reviews and generate in depth code edits. |
Summary and upcoming operate
In this put up, we introduced an ML-help aspect to decrease the time used on code overview similar variations. At the minute, a substantial amount of all actionable code evaluate comments on supported languages are resolved with utilized ML-instructed edits at Google. A 12-7 days A/B experiment throughout all Google developers will even further evaluate the effects of the element on the in general developer productivity.
We are doing the job on enhancements all over the entire stack. This incorporates increasing the excellent and remember of the model and building a much more streamlined experience for the developer with enhanced discoverability in the course of the evaluate method. As part of this, we are investigating the option of exhibiting proposed edits to the reviewer although they draft reviews and increasing the aspect into the IDE to help code-modify authors to get prompt code edits for natural-language commands.
Acknowledgements
This is the operate of many folks in Google Main Techniques & Experiences staff, Google Exploration, and DeepMind. We might like to specially thank Peter Choy for bringing the collaboration alongside one another, and all of our workforce members for their important contributions and handy assistance, such as Marcus Revaj, Gabriela Surita, Maxim Tabachnyk, Jacob Austin, Nimesh Ghelani, Dan Zheng, Peter Josling, Mariana Stariolo, Chris Gorgolewski, Sascha Varkevisser, Katja Grünwedel, Alberto Elizondo, Tobias Welp, Paige Bailey, Pierre-Antoine Manzagol, Pascal Lamblin, Chenjie Gu, Petros Maniatis, Henryk Michalewski, Sara Wiltberger, Ambar Murillo, Satish Chandra, Madhura Dudhgaonkar, Niranjan Tulpule, Zoubin Ghahramani, Juanjo Carin, Danny Tarlow, Kevin Villela, Stoyan Nikolov, David Tattersall, Boris Bokowski, Kathy Nix, Mehdi Ghissassi, Luis C. Cobo, Yujia Li, David Choi, Kristóf Molnár, Vahid Meimand, Amit Patel, Brett Wiltshire, Laurent Le Brun, Mingpan Guo, Hermann Unfastened, Jonas Mattes, Savinee Dancs.
[ad_2]
Resource url