
[ad_1]
Latent diffusion models have considerably increased in attractiveness in current years. Because their remarkable creating abilities, these versions can deliver higher-fidelity artificial datasets that can be extra to supervised equipment studying pipelines in situations when schooling data is scarce, like health-related imaging. In addition, these types of health-related imaging datasets generally will need to be annotated by qualified healthcare pros who are ready to decipher modest but semantically significant graphic areas. Latent diffusion styles may well be equipped to give an effortless process for manufacturing synthetic health-related imaging details by eliciting pertinent health care key phrases or concepts of fascination.
A Stanford study workforce investigated the representational limits of substantial eyesight-language basis types and evaluated how to use pre-trained foundational types to signify clinical imaging reports and principles. A lot more particularly, they investigated the Secure Diffusion model’s representational capability to evaluate the usefulness of both equally its language and vision encoders.
Chest X-rays (CXRs), the most common imaging system globally, ended up utilised by the authors. These CXRs arrived from two publicly accessible databases, CheXpert and MIMIC-CXR. 1000 frontal radiographs with their corresponding experiences had been randomly picked from every single dataset.
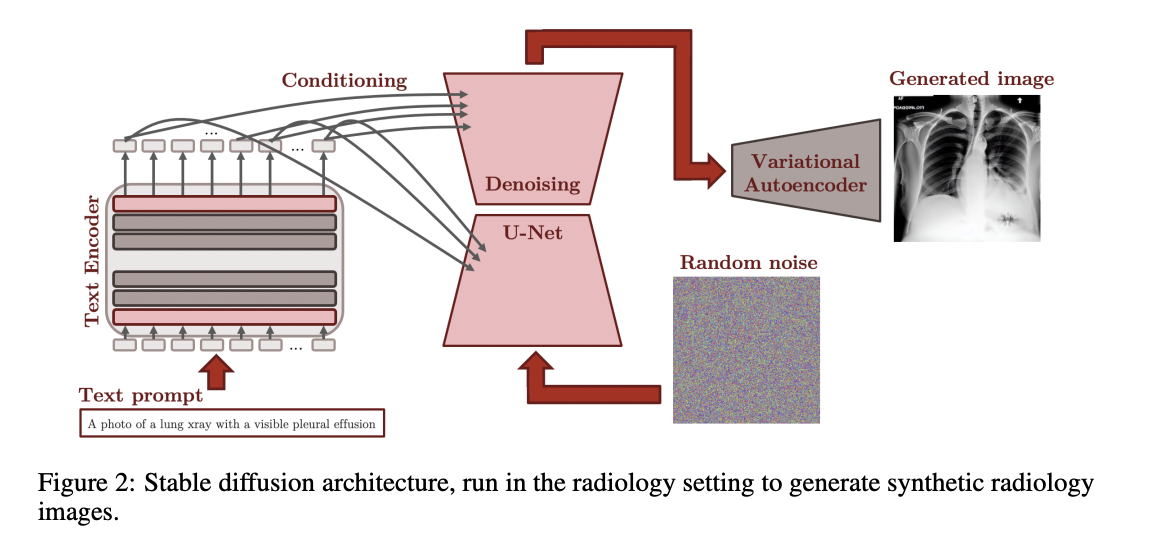
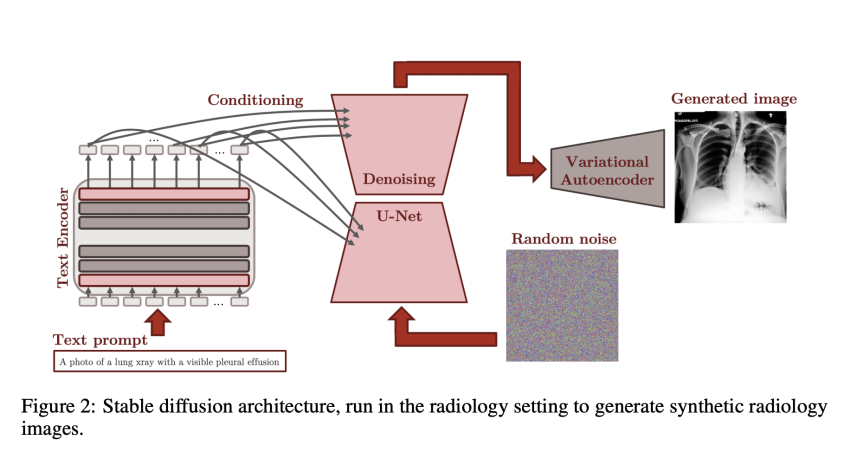
A CLIP text encoder is integrated with the Steady Diffusion pipeline (figure over) and parses textual content prompts to create a 768-dimensional latent illustration. This illustration is then made use of to ailment a denoising U-Internet to produce photographs in the latent impression space employing random noise as initialization. Inevitably, this latent representation is mapped to the pixel place by way of a variational autoencoder’s decoder element.
The authors initially investigated irrespective of whether the textual content encoder on your own is capable of projecting scientific prompts to the textual content latent house while protecting clinically important information (1) and whether or not the VAE by yourself is capable of reconstructing radiology illustrations or photos with no getting rid of clinically major features (2). And lastly, they proposed a few strategies for great-tuning the stable diffusion design in the radiology area (3).
1.VAE
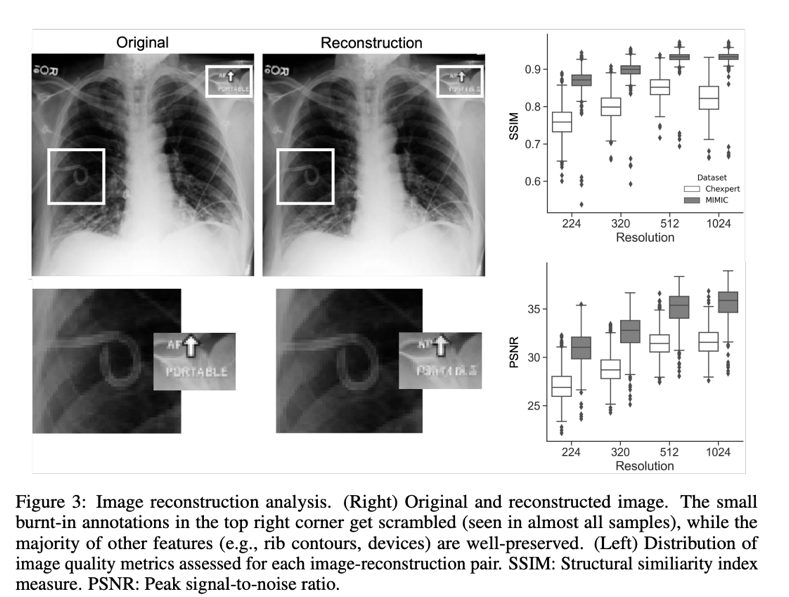
Steady Diffusion, a latent diffusion product, makes use of an encoder properly trained to exclude high-frequency specifics that reflect perceptually insignificant qualities to completely transform picture inputs into a latent area right before completing the generative denoising approach. CXR pictures sampled from CheXpert or MIMIC (“originals”) were encoded to latent representations and rebuilt into visuals (“reconstructions”) to study how nicely medical imaging data is preserved whilst passing thorugh the VAE. The root-necessarily mean-sq. mistake (RMSE) and other metrics, these as the Fréchet inception length (FID), had been calculated to objectively evaluate the reconstruction’s top quality, when a senior radiologist with 7 many years of abilities evaluated it qualitatively. A design that experienced been pretrained to understand 18 distinct ailments was utilised to examine how the reconstruction method affected classification functionality. The graphic under is a reconstruction instance.
2.Textual content Encoder
The aim of this challenge is to be able to situation the technology of illustrations or photos on linked health care problems that can be communicated by means of a text prompt in the context-particular setting of radiology studies and photos (e.g., in the type of a report). Due to the fact the relaxation of the Secure Diffusion approach depends on the text encoder’s capacity to precisely represent medical options in the latent space, the authors investigated this situation making use of a procedure based on earlier revealed pre-qualified language styles in the place.
3.High-quality-tuning
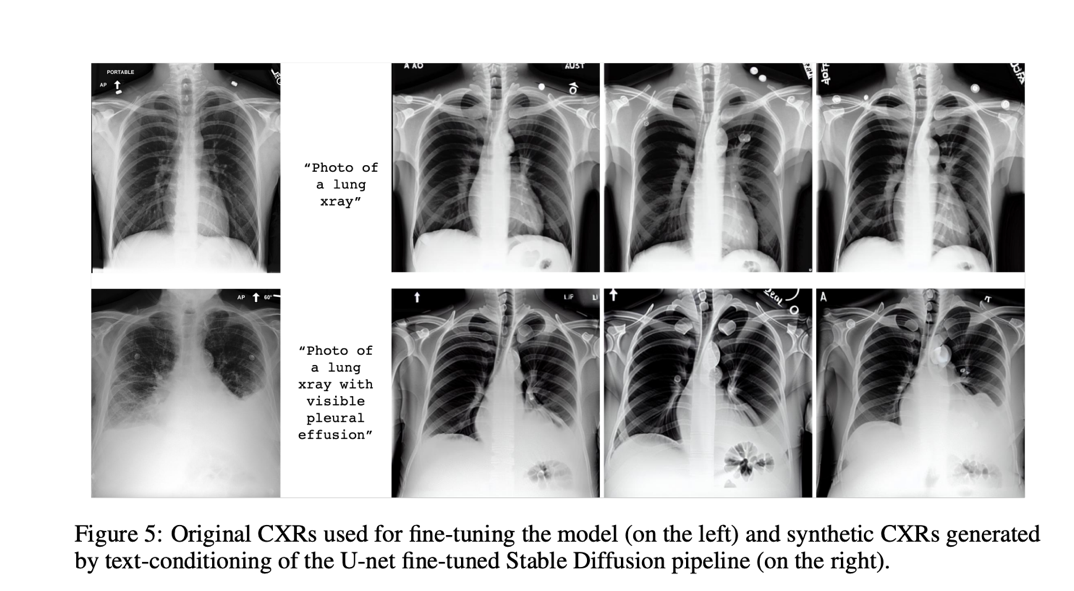
To create area-distinct visuals, many procedures had been experimented with. In the initially experiment, the authors swapped out the CLIP textual content encoder—which experienced been kept frozen throughout the original Stable Diffusion training—for a text encoder that experienced presently been pre-trained on information from the biomedical or radiology fields. In the 2nd, the textual content encoder embeddings ended up the most important emphasis though the Secure Diffusion product was modified. In this scenario, a new token is introduced that can be applied to outline features at the affected person, course of action, or anomaly concentrations. The third 1 uses domain-specific visuals to great-tune all parts apart from the U-net. Right after attainable good-tuning by one particular of the scenarios, the different generative designs ended up put to the examination with two simple prompts: “A photograph of a lung x-ray” and “A snapshot of a lung x-ray with a obvious pleural effusion.” The types manufactured synthetic illustrations or photos only centered on this text-conditioning. The U-Internet high-quality-tuning process stands out amongst the some others as the most promising since it achieves the lowest FID-scores and, unsurprisingly, creates the most sensible benefits, proving that these kinds of generative products are able of mastering radiology principles and can be utilised to insert reasonable-wanting abnormalities.
Examine out the Paper. All Credit history For This Investigation Goes To the Scientists on This Challenge. Also, don’t overlook to join our 17k+ ML SubReddit, Discord Channel, and Electronic mail Publication, where we share the most current AI research information, awesome AI tasks, and much more.
Leonardo Tanzi is presently a Ph.D. Student at the Polytechnic College of Turin, Italy. His present exploration focuses on human-machine methodologies for good assistance all through elaborate interventions in the health-related domain, applying Deep Learning and Augmented Reality for 3D guidance.
[ad_2]
Source backlink