
[ad_1]
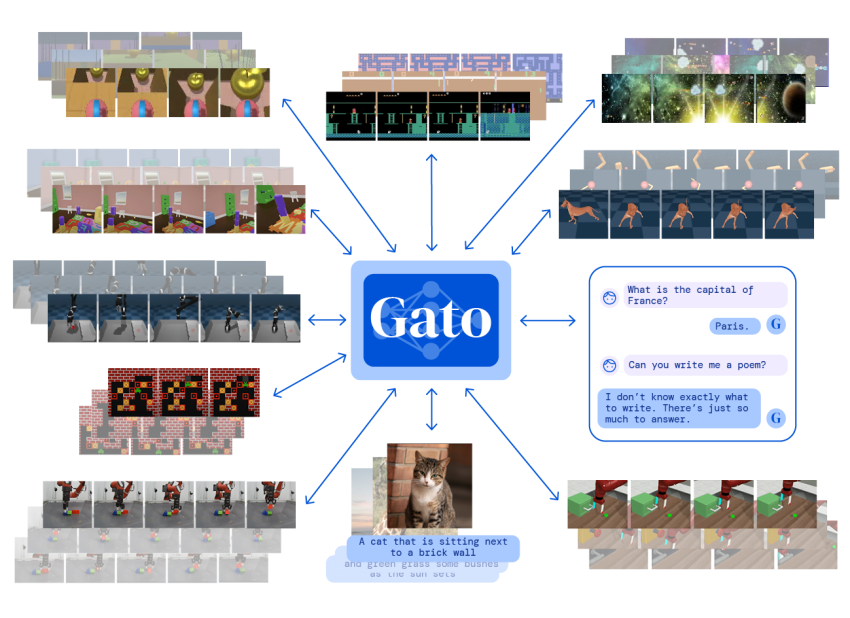
Impressed by progress in significant-scale language modelling, we implement a similar strategy in the direction of developing a solitary generalist agent further than the realm of text outputs. The agent, which we refer to as Gato, is effective as a multi-modal, multi-activity, multi-embodiment generalist coverage. The similar network with the same weights can enjoy Atari, caption photographs, chat, stack blocks with a genuine robot arm and a lot much more, selecting dependent on its context irrespective of whether to output textual content, joint torques, button presses, or other tokens.

All through the training stage of Gato, info from different responsibilities and modalities are serialised into a flat sequence of tokens, batched, and processed by a transformer neural network very similar to a significant language model. The decline is masked so that Gato only predicts motion and textual content targets.
-1.png)
When deploying Gato, a prompt, this kind of as a demonstration, is tokenised, forming the first sequence. Up coming, the setting yields the to start with observation, which is also tokenised and appended to the sequence. Gato samples the action vector autoregressively, just one token at a time.
When all tokens comprising the motion vector have been sampled (determined by the motion specification of the atmosphere), the action is decoded and sent to the ecosystem which methods and yields a new observation. Then the procedure repeats. The design generally sees all previous observations and steps inside its context window of 1024 tokens.

Gato is trained on a significant amount of datasets comprising agent experience in the two simulated and real-planet environments, in addition to a wide variety of normal language and impression datasets. The selection of jobs, in which the functionality of the pretrained Gato design is over a proportion of professional rating, grouped by area, is demonstrated listed here.

The subsequent photos also present how the pre-skilled Gato design with the identical weights can do picture captioning, interact in an interactive dialogue, and control a robotic arm, between many other tasks.



[ad_2]
Supply url