
[ad_1]
In deep reinforcement studying, an agent uses a neural community to map observations to a plan or return prediction. This network’s functionality is to change observations into a sequence of progressively finer qualities, which the closing layer then linearly brings together to get the desired prediction. The agent’s illustration of its recent state is how most persons look at this modify and the intermediate traits it results in. In accordance to this standpoint, the finding out agent carries out two responsibilities: illustration discovering, which will involve obtaining important condition qualities, and credit assignment, which involves translating these capabilities into exact predictions.
Contemporary RL procedures usually incorporate machinery that incentivizes studying very good condition representations, such as predicting fast rewards, potential states, or observations, encoding a similarity metric, and facts augmentation. Stop-to-conclude RL has been demonstrated to get superior effectiveness in a large selection of difficulties. It is frequently possible and desirable to purchase a adequately wealthy illustration just before executing credit history assignment illustration finding out has been a core part of RL considering the fact that its inception. Employing the network to forecast extra jobs relevant to each and every point out is an efficient way to understand condition representations.
A collection of attributes corresponding to the main elements of the auxiliary process matrix may perhaps be demonstrated as becoming induced by further responsibilities in an idealized environment. Hence, the acquired representation’s theoretical approximation error, generalization, and stability might be examined. It may well appear as a surprise to study how minor is known about their carry out in much larger-scale surroundings. It is continue to decided how using extra jobs or increasing the network’s potential would have an affect on the scaling capabilities of representation learning from auxiliary things to do. This essay seeks to shut that information gap. They use a relatives of further incentives that may perhaps be sampled as a setting up issue for their method.
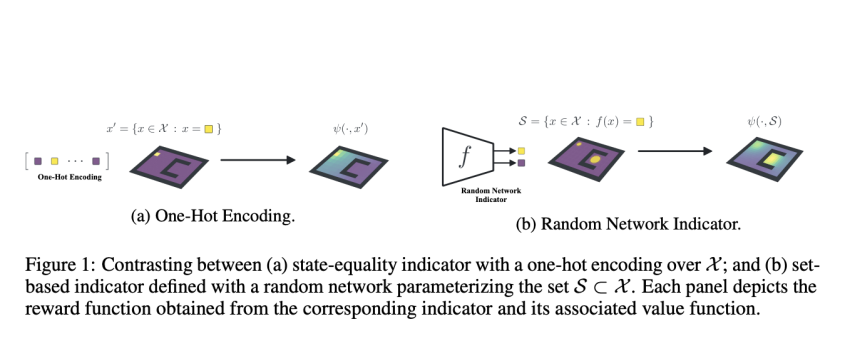
Researchers from McGill College, Université de Montréal, Québec AI Institute, College of Oxford and Google Analysis specially apply the successor measure, which expands the successor representation by substituting established inclusion for point out equality. In this scenario, a family of binary functions more than states serves as an implicit definition for these sets. Most of their investigation is targeted on binary operations received from randomly initialized networks, which have presently been revealed to be valuable as random cumulants. Despite the chance that their conclusions would also use to other auxiliary benefits, their technique has numerous pros:
- It can be effortlessly scaled up utilizing further random community samples as more jobs.
- It is instantly similar to the binary reward features discovered in deep RL benchmarks.
- It is partly easy to understand.
Predicting the predicted return of the random coverage for the pertinent auxiliary incentives is the real extra undertaking in the tabular setting, this corresponds to proto-price functions. They refer to their method as proto-value networks as a final result. They analysis how nicely this solution works in the arcade learning environment. When utilized with linear purpose approximation, they study the traits figured out by PVN and show how effectively they represent the temporal framework of the atmosphere. General, they find out that PVN only requirements a little part of interactions with the environment reward operate to produce point out attributes loaded plenty of to help linear price estimates equal to those people of DQN on various games.
They discovered in ablation study that increasing the price network’s capacity appreciably boosts the efficiency of their linear agents and that much larger networks can tackle extra employment. They also uncover, fairly unexpectedly, that their approach operates very best with what may possibly appear to be a modest selection of additional responsibilities: the smallest networks they analyze make their best representations from 10 or less duties, and the most important, from 50 to 100 tasks. They conclude that precise tasks may perhaps result in representations that are far richer than anticipated and that the impression of any given task on fastened-sizing networks however wants to be completely comprehended.
Examine out the Paper. Don’t neglect to join our 21k+ ML SubReddit, Discord Channel, and Electronic mail E-newsletter, where we share the latest AI analysis information, awesome AI projects, and much more. If you have any inquiries concerning the earlier mentioned posting or if we skipped anything at all, truly feel totally free to e mail us at [email protected]
🚀 Examine Out 100’s AI Resources in AI Applications Club
Aneesh Tickoo is a consulting intern at MarktechPost. He is at present pursuing his undergraduate diploma in Data Science and Artificial Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time performing on jobs aimed at harnessing the energy of machine learning. His investigation interest is graphic processing and is passionate about constructing methods close to it. He loves to join with persons and collaborate on interesting initiatives.
[ad_2]
Source website link