
[ad_1]
Reinforcement mastering (RL) has built remarkable development in modern many years toward addressing actual-lifetime problems – and offline RL built it even more realistic. Instead of direct interactions with the setting, we can now prepare quite a few algorithms from a solitary pre-recorded dataset. On the other hand, we drop the functional strengths in information-efficiency of offline RL when we consider the policies at hand.
For illustration, when coaching robotic manipulators the robot assets are generally restricted, and teaching quite a few policies by offline RL on a one dataset provides us a substantial information-performance gain when compared to on the web RL. Evaluating just about every plan is an expensive approach, which involves interacting with the robot hundreds of instances. When we pick out the best algorithm, hyperparameters, and a quantity of education techniques, the problem immediately will become intractable.
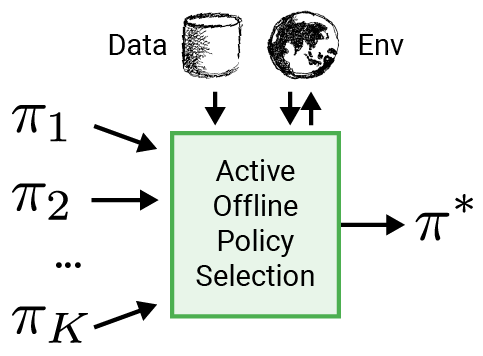
To make RL more relevant to authentic-environment programs like robotics, we suggest employing an clever analysis method to select the coverage for deployment, named energetic offline coverage range (A-OPS). In A-OPS, we make use of the prerecorded dataset and permit restricted interactions with the authentic setting to increase the selection high quality.
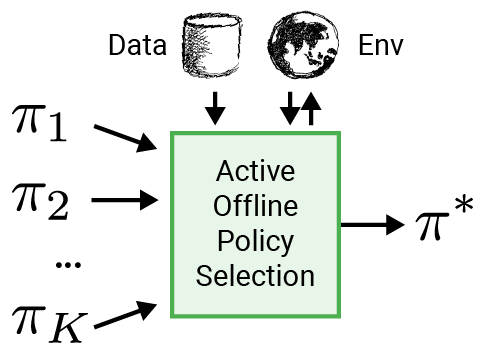
To minimise interactions with the genuine natural environment, we employ three crucial functions:
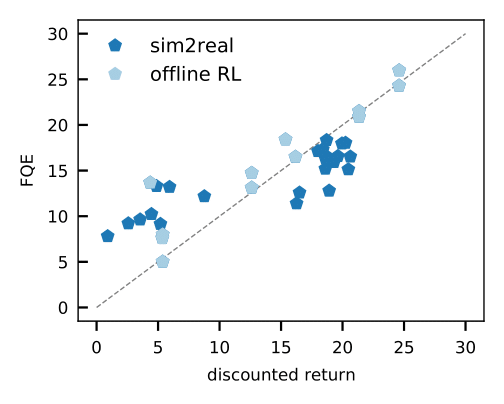
- Off-policy coverage analysis, these kinds of as equipped Q-analysis (FQE), enables us to make an preliminary guess about the general performance of each and every policy based mostly on an offline dataset. It correlates perfectly with the ground fact efficiency in many environments, including real-globe robotics wherever it is used for the very first time.
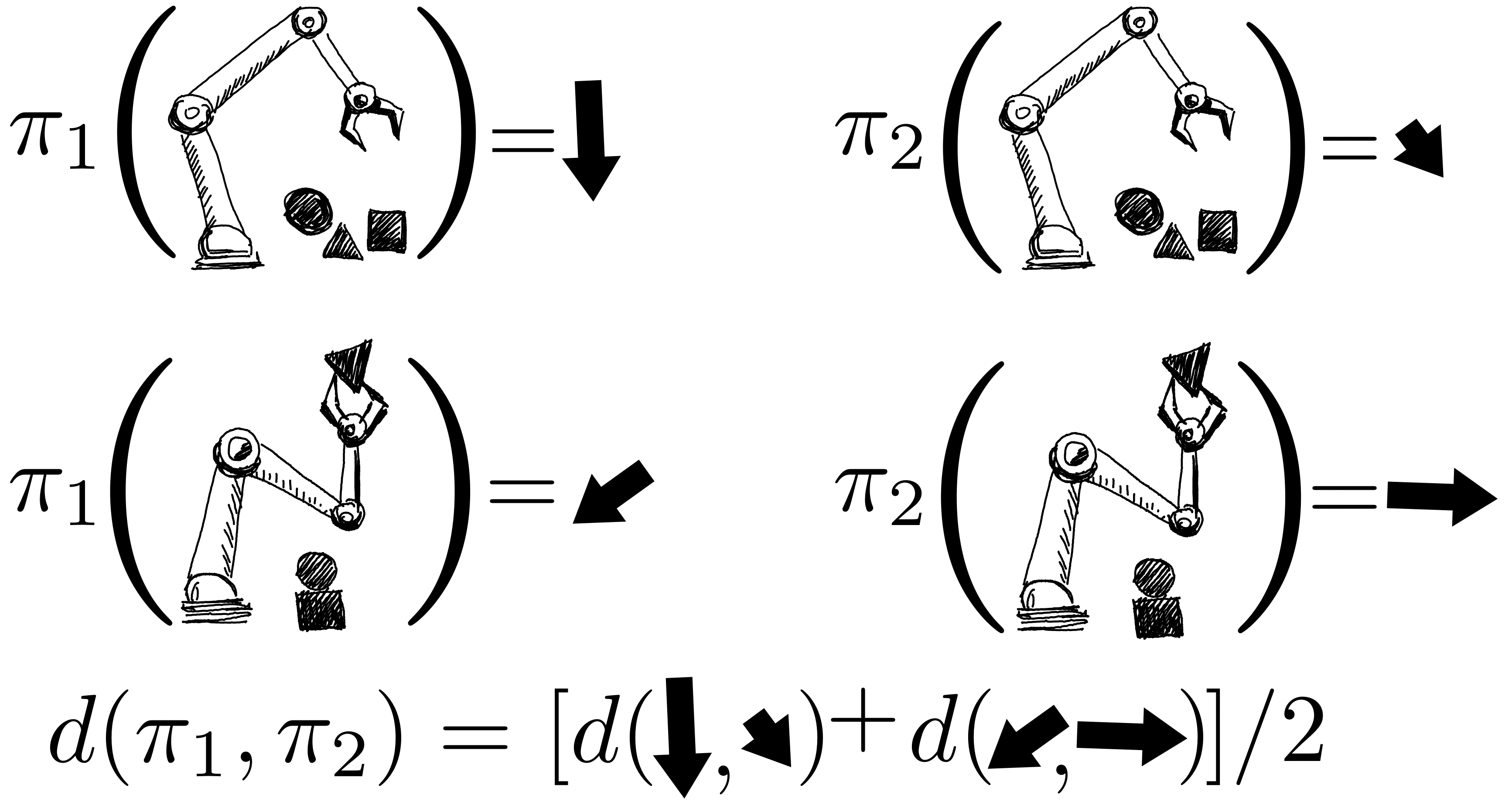
The returns of the insurance policies are modelled jointly utilizing a Gaussian approach, exactly where observations include things like FQE scores and a small quantity of newly collected episodic returns from the robot. After analyzing a single coverage, we obtain expertise about all procedures due to the fact their distributions are correlated via the kernel in between pairs of insurance policies. The kernel assumes that if policies take similar actions – this sort of as shifting the robotic gripper in a comparable direction – they are likely to have comparable returns.
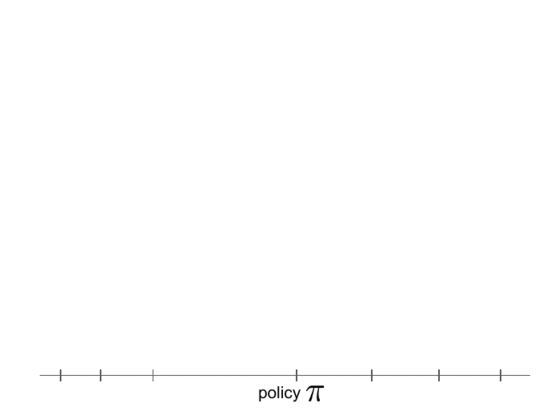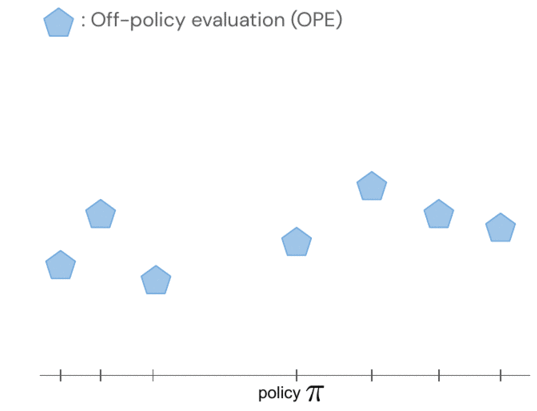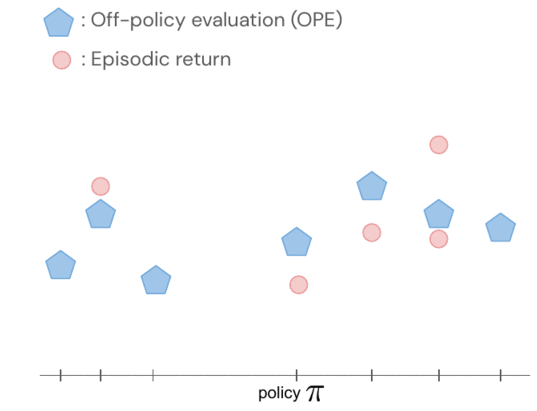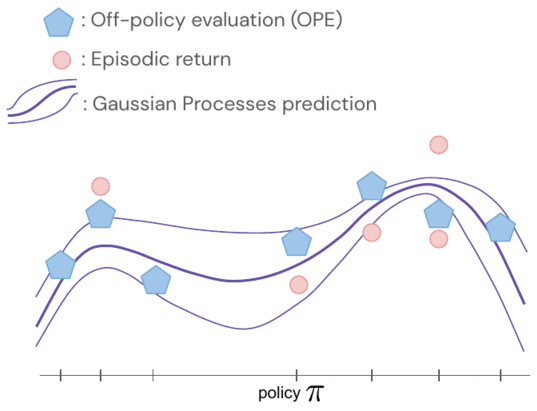
- To be extra data-efficient, we implement Bayesian optimisation and prioritise additional promising policies to be evaluated future, specifically those that have large predicted performance and significant variance.
We shown this treatment in a range of environments in several domains: dm-manage, Atari, simulated, and actual robotics. Employing A-OPS lessens the regret swiftly, and with a average selection of coverage evaluations, we determine the finest policy.
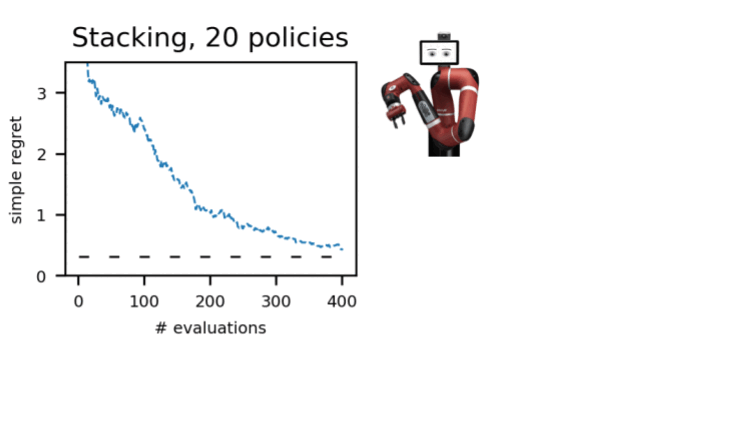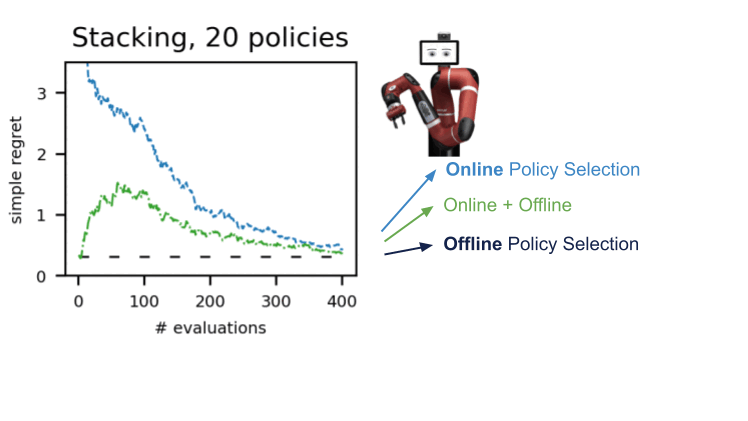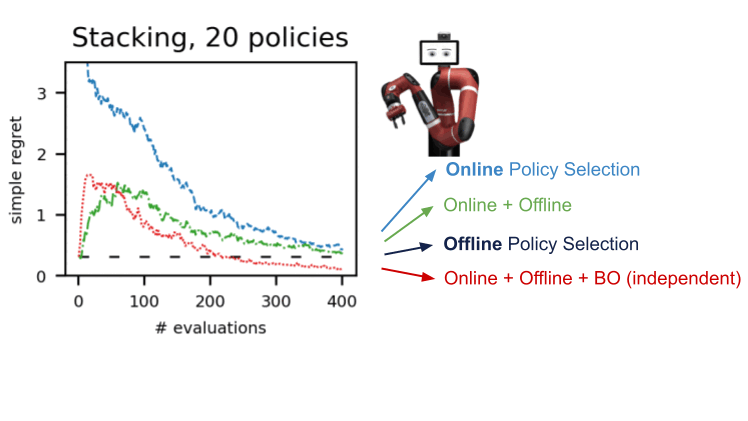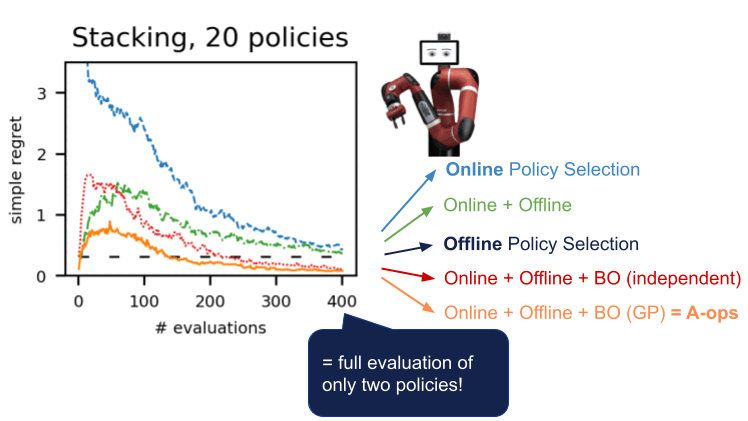
Our success advise that it’s attainable to make an effective offline plan selection with only a modest quantity of natural environment interactions by utilising the offline facts, particular kernel, and Bayesian optimisation. The code for A-OPS is open up-sourced and obtainable on GitHub with an instance dataset to try out.
[ad_2]
Resource hyperlink