
[ad_1]
Deep studying has not long ago pushed great development in a wide array of apps, ranging from realistic picture era and outstanding retrieval systems to language models that can hold human-like conversations. When this progress is incredibly fascinating, the prevalent use of deep neural network versions necessitates warning: as guided by Google’s AI Rules, we seek to develop AI technologies responsibly by comprehension and mitigating likely dangers, such as the propagation and amplification of unfair biases and defending user privacy.
Entirely erasing the affect of the information requested to be deleted is hard considering the fact that, aside from just deleting it from databases wherever it’s stored, it also demands erasing the impact of that data on other artifacts these kinds of as experienced equipment studying designs. Additionally, latest investigation [1, 2] has proven that in some instances it could be feasible to infer with substantial accuracy whether or not an illustration was applied to prepare a device studying product applying membership inference attacks (MIAs). This can elevate privateness concerns, as it implies that even if an individual’s data is deleted from a databases, it may perhaps however be probable to infer regardless of whether that individual’s details was employed to coach a model.
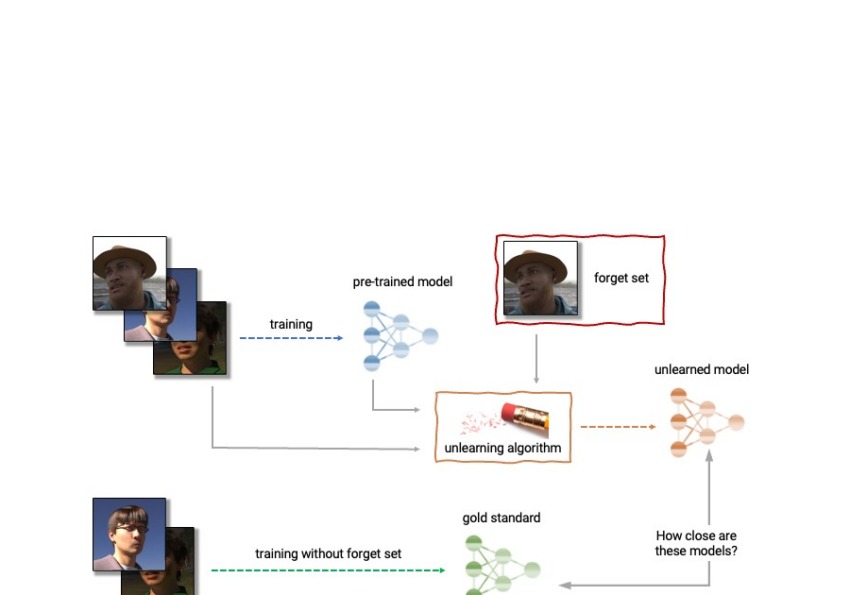
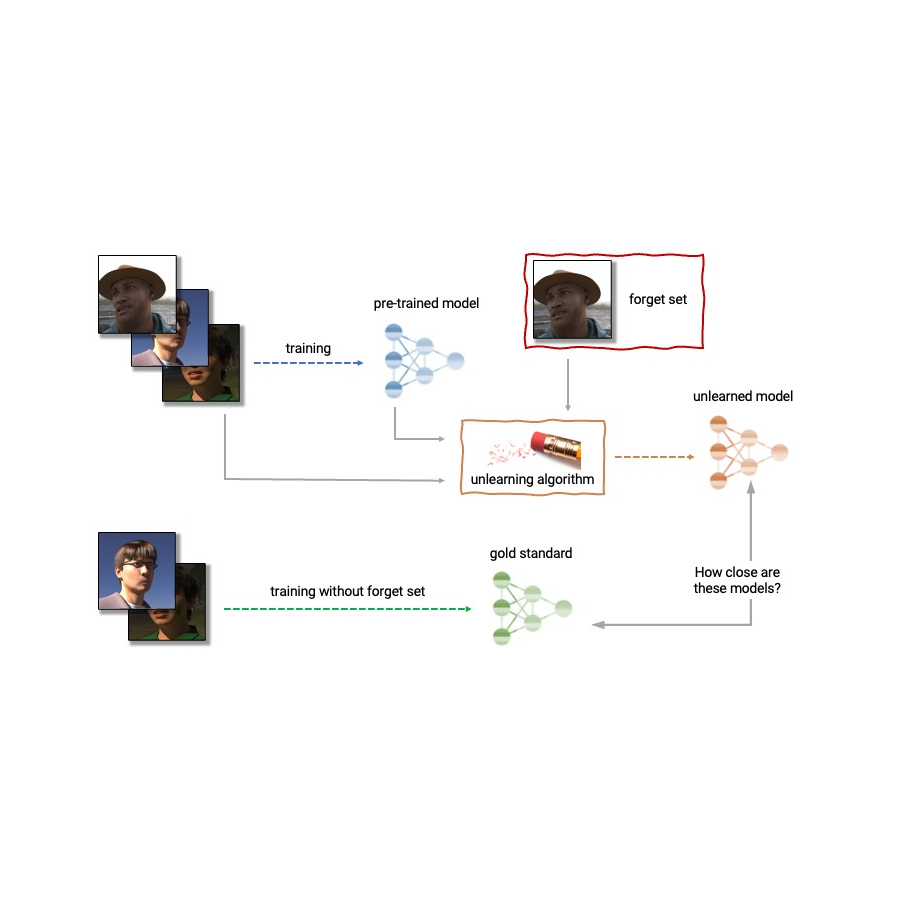
Offered the previously mentioned, device unlearning is an emergent subfield of machine studying that aims to get rid of the affect of a unique subset of coaching examples — the “forget established” — from a trained design. Additionally, an excellent unlearning algorithm would eliminate the impact of specific examples whilst retaining other advantageous homes, this kind of as the accuracy on the relaxation of the practice set and generalization to held-out illustrations. A easy way to create this unlearned product is to retrain the design on an adjusted coaching established that excludes the samples from the fail to remember set. Even so, this is not normally a practical option, as retraining deep styles can be computationally costly. An great unlearning algorithm would rather use the previously-trained model as a commencing stage and efficiently make adjustments to clear away the influence of the asked for data.
Nowadays we are thrilled to announce that we have teamed up with a wide team of educational and industrial scientists to arrange the first Equipment Unlearning Obstacle. The level of competition considers a practical situation in which immediately after coaching, a sure subset of the schooling images need to be overlooked to shield the privacy or rights of the persons involved. The opposition will be hosted on Kaggle, and submissions will be instantly scored in terms of both of those forgetting high quality and product utility. We hope that this competition will help progress the point out of the artwork in equipment unlearning and inspire the improvement of successful, efficient and moral unlearning algorithms.
Device unlearning apps
Machine unlearning has apps over and above safeguarding user privateness. For instance, a single can use unlearning to erase inaccurate or outdated info from properly trained models (e.g., because of to problems in labeling or modifications in the atmosphere) or take away harmful, manipulated, or outlier details.
The industry of equipment unlearning is associated to other places of equipment finding out these as differential privacy, life-very long mastering, and fairness. Differential privateness aims to guarantee that no specific education illustration has way too significant an influence on the trained design a more powerful objective as opposed to that of unlearning, which only needs erasing the influence of the selected ignore set. Life-long discovering analysis aims to design models that can master consistently even though sustaining formerly-obtained techniques. As work on unlearning progresses, it might also open up further means to improve fairness in models, by correcting unfair biases or disparate cure of members belonging to distinctive teams (e.g., demographics, age groups, and many others.).
 |
| Anatomy of unlearning. An unlearning algorithm will take as input a pre-experienced design and 1 or a lot more samples from the practice set to unlearn (the “fail to remember set”). From the design, forget about established, and keep established, the unlearning algorithm makes an up-to-date product. An excellent unlearning algorithm provides a model that is indistinguishable from the product skilled without the fail to remember set. |
Troubles of device unlearning
The trouble of unlearning is complex and multifaceted as it includes numerous conflicting goals: forgetting the asked for data, keeping the model’s utility (e.g., accuracy on retained and held-out knowledge), and performance. For the reason that of this, present unlearning algorithms make different trade-offs. For case in point, full retraining achieves profitable forgetting without harming model utility, but with bad effectiveness, while adding noise to the weights achieves forgetting at the cost of utility.
Also, the analysis of forgetting algorithms in the literature has so considerably been remarkably inconsistent. Whilst some will work report the classification precision on the samples to unlearn, some others report distance to the fully retrained model, and nevertheless many others use the error amount of membership inference assaults as a metric for forgetting quality [4, 5, 6].
We consider that the inconsistency of evaluation metrics and the deficiency of a standardized protocol is a serious impediment to progress in the field — we are not able to make immediate comparisons in between distinct unlearning strategies in the literature. This leaves us with a myopic view of the relative deserves and negatives of distinct approaches, as well as open difficulties and chances for building improved algorithms. To tackle the concern of inconsistent evaluation and to advance the state of the artwork in the discipline of equipment unlearning, we’ve teamed up with a broad group of tutorial and industrial researchers to organize the very first unlearning obstacle.
Saying the very first Machine Unlearning Obstacle
We are delighted to announce the initial Equipment Unlearning Obstacle, which will be held as aspect of the NeurIPS 2023 Competitiveness Track. The aim of the competitors is twofold. To start with, by unifying and standardizing the analysis metrics for unlearning, we hope to discover the strengths and weaknesses of unique algorithms via apples-to-apples comparisons. 2nd, by opening this level of competition to anyone, we hope to foster novel alternatives and lose light-weight on open challenges and opportunities.
The levels of competition will be hosted on Kaggle and run concerning mid-July 2023 and mid-September 2023. As section of the competition, currently we’re announcing the availability of the beginning package. This commencing kit gives a foundation for contributors to make and check their unlearning designs on a toy dataset.
The opposition considers a practical situation in which an age predictor has been qualified on experience illustrations or photos, and, following teaching, a certain subset of the coaching photos ought to be forgotten to safeguard the privateness or rights of the folks concerned. For this, we will make accessible as component of the starting kit a dataset of artificial faces (samples shown under) and we’ll also use a number of serious-experience datasets for evaluation of submissions. The members are requested to post code that takes as enter the skilled predictor, the forget and keep sets, and outputs the weights of a predictor that has unlearned the designated overlook set. We will evaluate submissions dependent on both equally the strength of the forgetting algorithm and model utility. We will also enforce a hard slash-off that rejects unlearning algorithms that run slower than a fraction of the time it normally takes to retrain. A worthwhile result of this competition will be to characterize the trade-offs of different unlearning algorithms.
 |
| Excerpt visuals from the Experience Synthetics dataset collectively with age annotations. The level of competition considers the state of affairs in which an age predictor has been qualified on encounter illustrations or photos like the previously mentioned, and, soon after coaching, a selected subset of the education photos will have to be overlooked. |
For assessing forgetting, we will use equipment influenced by MIAs, these types of as LiRA. MIAs have been first produced in the privateness and security literature and their aim is to infer which examples had been section of the education established. Intuitively, if unlearning is thriving, the unlearned design has no traces of the overlooked illustrations, leading to MIAs to fall short: the attacker would be unable to infer that the forget about set was, in fact, section of the primary schooling established. In addition, we will also use statistical checks to quantify how various the distribution of unlearned designs (produced by a unique submitted unlearning algorithm) is when compared to the distribution of designs retrained from scratch. For an perfect unlearning algorithm, these two will be indistinguishable.
Conclusion
Equipment unlearning is a highly effective tool that has the potential to deal with numerous open challenges in equipment learning. As analysis in this spot carries on, we hope to see new solutions that are extra productive, efficient, and liable. We are thrilled to have the chance by way of this levels of competition to spark curiosity in this discipline, and we are hunting ahead to sharing our insights and conclusions with the neighborhood.
Acknowledgements
The authors of this put up are now component of Google DeepMind. We are crafting this site put up on behalf of the firm crew of the Unlearning Levels of competition: Eleni Triantafillou*, Fabian Pedregosa* (*equivalent contribution), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Sunshine Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera and Isabelle Guyon.
[ad_2]
Source hyperlink