
[ad_1]
TLDR: Textual content Prompt -> LLM -> Intermediate Representation (this kind of as an image structure) -> Secure Diffusion -> Image.
The latest developments in textual content-to-picture technology with diffusion designs have yielded amazing benefits synthesizing very realistic and varied visuals. Even so, inspite of their extraordinary capabilities, diffusion styles, these as Secure Diffusion, often battle to correctly follow the prompts when spatial or typical feeling reasoning is expected.
The following figure lists 4 scenarios in which Stable Diffusion falls quick in making photographs that precisely correspond to the presented prompts, particularly negation, numeracy, and attribute assignment, spatial relationships. In contrast, our strategy, LLM-grounded Diffusion (LMD), delivers considerably better prompt comprehending in textual content-to-image era in people situations.

Determine 1: LLM-grounded Diffusion boosts the prompt being familiar with ability of text-to-image diffusion types.
A single doable option to handle this problem is of study course to assemble a broad multi-modal dataset comprising intricate captions and practice a substantial diffusion product with a huge language encoder. This tactic comes with significant costs: It is time-consuming and high priced to train each massive language versions (LLMs) and diffusion types.
Our Remedy
To effectively resolve this challenge with negligible cost (i.e., no instruction expenditures), we in its place equip diffusion styles with increased spatial and widespread perception reasoning by working with off-the-shelf frozen LLMs in a novel two-phase generation approach.
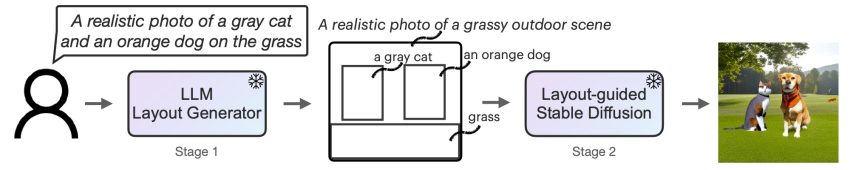
To start with, we adapt an LLM to be a text-guided layout generator via in-context mastering. When presented with an picture prompt, an LLM outputs a scene format in the sort of bounding containers along with corresponding specific descriptions. Next, we steer a diffusion product with a novel controller to generate images conditioned on the format. Both stages benefit from frozen pretrained types devoid of any LLM or diffusion model parameter optimization. We invite audience to go through the paper on arXiv for additional facts.
Determine 2: LMD is a text-to-impression generative design with a novel two-phase technology method: a text-to-layout generator with an LLM + in-context discovering and a novel format-guided stable diffusion. Both of those phases are coaching-no cost.
LMD’s Extra Abilities
Moreover, LMD by natural means lets dialog-centered multi-round scene specification, enabling further clarifications and subsequent modifications for each and every prompt. In addition, LMD is equipped to cope with prompts in a language that is not effectively-supported by the fundamental diffusion product.

Determine 3: Incorporating an LLM for prompt knowing, our technique is capable to conduct dialog-based scene specification and generation from prompts in a language (Chinese in the illustration over) that the fundamental diffusion model does not assist.
Supplied an LLM that supports multi-spherical dialog (e.g., GPT-3.5 or GPT-4), LMD allows the consumer to give added information or clarifications to the LLM by querying the LLM just after the 1st structure generation in the dialog and generate photographs with the current layout in the subsequent reaction from the LLM. For instance, a user could ask for to add an object to the scene or improve the current objects in area or descriptions (the still left 50 % of Determine 3).
Also, by giving an instance of a non-English prompt with a structure and background description in English through in-context learning, LMD accepts inputs of non-English prompts and will deliver layouts, with descriptions of bins and the background in English for subsequent format-to-impression era. As revealed in the ideal half of Determine 3, this will allow generation from prompts in a language that the underlying diffusion types do not support.
Visualizations
We validate the superiority of our design by comparing it with the base diffusion design (SD 2.1) that LMD takes advantage of less than the hood. We invite readers to our get the job done for a lot more analysis and comparisons.
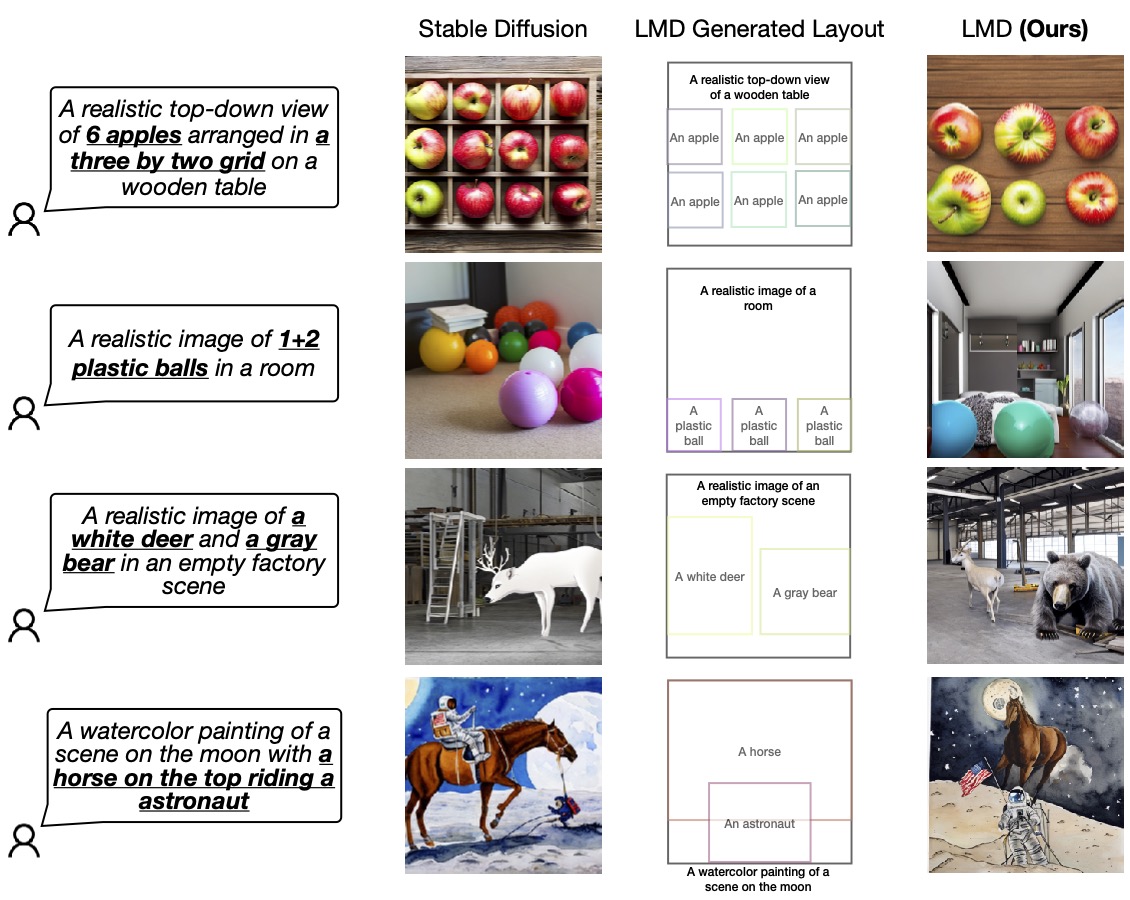
Figure 4: LMD outperforms the foundation diffusion design in properly making visuals in accordance to prompts that necessitate both equally language and spatial reasoning. LMD also enables counterfactual textual content-to-graphic era that the base diffusion product is not able to make (the last row).
For a lot more aspects about LLM-grounded Diffusion (LMD), check out our internet site and read the paper on arXiv.
BibTex
If LLM-grounded Diffusion evokes your do the job, remember to cite it with:
@short articlelian2023llmgrounded,
title=LLM-grounded Diffusion: Maximizing Prompt Being familiar with of Text-to-Graphic Diffusion Designs with Substantial Language Designs,
author=Lian, Extensive and Li, Boyi and Yala, Adam and Darrell, Trevor,
journal=arXiv preprint arXiv:2305.13655,
calendar year=2023
[ad_2]
Source website link