

[ad_1]
It’s apparent from the sum of information protection, posts, weblogs, and drinking water cooler stories that artificial intelligence (AI) and equipment understanding (ML) are altering our modern society in essential ways—and that the sector is evolving swiftly to check out to maintain up with the explosive expansion.
Sad to say, the network that we have utilised in the past for large-functionality computing (HPC) are not able to scale to meet the needs of AI/ML. As an business, we will have to evolve our wondering and establish a scalable and sustainable community for AI/ML.
These days, the business is fragmented in between AI/ML networks designed around 4 one of a kind architectures: InfiniBand, Ethernet, telemetry assisted Ethernet, and completely scheduled fabrics.
Every technological know-how has its execs and disadvantages, and various tier 1 world wide web scalers perspective the trade-offs in different ways. This is why we see the market transferring in numerous directions concurrently to meet up with the speedy huge-scale buildouts taking place now.
This fact is at the coronary heart of the benefit proposition of Cisco Silicon A person.
Clients can deploy Cisco Silicon One to electrical power their AI/ML networks and configure the community to use normal Ethernet, telemetry assisted Ethernet, or thoroughly scheduled materials. As workloads evolve, they can continue to evolve their thinking with Cisco Silicon One’s programmable architecture.
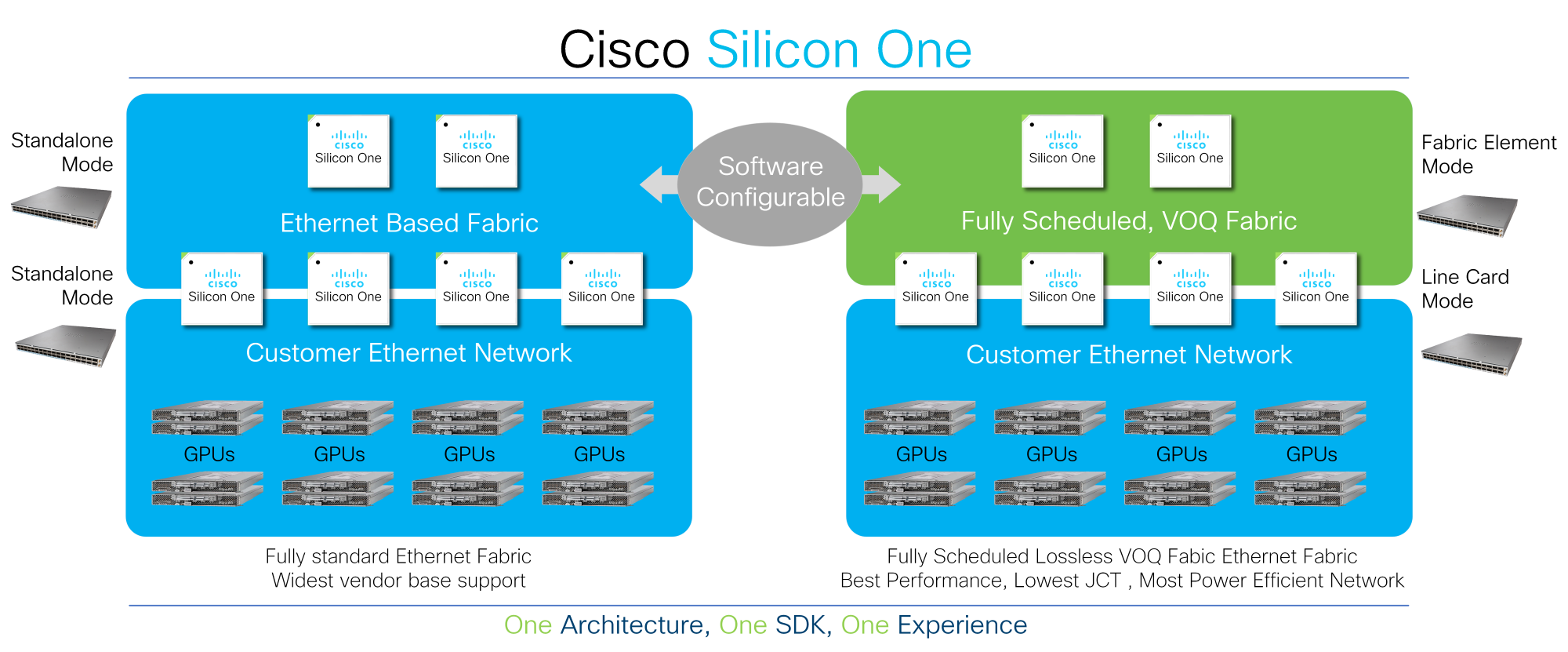
All other silicon architectures on the industry lock corporations into a slender deployment model, forcing consumers to make early getting time choices and limiting their versatility to evolve. Cisco Silicon One, having said that, offers consumers the flexibility to system their network into various operational modes and supplies very best-of-breed qualities in each method. Simply because Cisco Silicon Just one can enable a number of architectures, customers can concentrate on the truth of the info and then make details-driven selections according to their personal criteria.

To support fully grasp the relative deserves of just about every of these systems, it is crucial to realize the fundamentals of AI/ML. Like several buzzwords, AI/ML is an oversimplification of quite a few distinctive systems, use circumstances, targeted traffic designs, and necessities. To simplify the dialogue, we’ll target on two factors: education clusters and inference clusters.
Teaching clusters are developed to make a design using regarded data. These clusters practice the model. This is an exceptionally elaborate iterative algorithm that is run throughout a huge number of GPUs and can run for many months to create a new design.
Inference clusters, in the meantime, get a educated design to examine unknown info and infer the solution. Just put, these clusters infer what the unfamiliar knowledge is with an already qualified product. Inference clusters are a lot smaller computational types. When we interact with OpenAI’s ChatGPT, or Google Bard, we are interacting with the inference types. These types are a outcome of a pretty substantial education of the design with billions or even trillions of parameters in excess of a prolonged time period of time.
In this web site, we’ll emphasis on coaching clusters and evaluate how the efficiency of Ethernet, telemetry assisted Ethernet, and thoroughly scheduled materials behave. I shared more details about this subject in my OCP Worldwide Summit, Oct 2022 presentation.
AI/ML training networks are created as self-contained, enormous again-conclusion networks and have appreciably different traffic styles than conventional entrance-conclude networks. These back-conclusion networks are made use of to carry specialised targeted traffic in between specialized endpoints. In the previous, they had been employed for storage interconnect, nevertheless, with the arrival of distant direct memory obtain (RDMA) and RDMA about Converged Ethernet (RoCE), a important portion of storage networks are now constructed over generic Ethernet.
Today, these back again-conclude networks are becoming employed for HPC and enormous AI/ML instruction clusters. As we noticed with storage, we are witnessing a migration away from legacy protocols.
The AI/ML training clusters have one of a kind targeted visitors styles compared to common front-finish networks. The GPUs can thoroughly saturate substantial-bandwidth hyperlinks as they send the benefits of their computations to their peers in a facts transfer known as the all-to-all collective. At the conclude of this transfer, a barrier procedure assures that all GPUs are up to date. This results in a synchronization celebration in the community that triggers GPUs to be idled, waiting around for the slowest path by means of the community to total. The work completion time (JCT) actions the effectiveness of the network to be certain all paths are doing perfectly.

This targeted traffic is non-blocking and effects in synchronous, substantial-bandwidth, lengthy-lived flows. It is vastly distinctive from the data styles in the front-end network, which are mostly created out of several asynchronous, small-bandwidth, and limited-lived flows, with some greater asynchronous prolonged-lived flows for storage. These distinctions alongside with the importance of the JCT imply network performance is important.
To assess how these networks carry out, we established a product of a smaller teaching cluster with 256 GPUs, 8 major of rack (TOR) switches, and four spine switches. We then employed an all-to-all collective to transfer a 64 MB collective sizing and vary the number of simultaneous careers jogging on the network, as properly as the amount of community in the speedup.
The results of the examine are remarkable.
In contrast to HPC, which was made for a single occupation, substantial AI/ML education clusters are made to run numerous simultaneous employment, equally to what happens in internet scale data facilities nowadays. As the quantity of employment boosts, the results of the load balancing scheme utilized in the community come to be additional clear. With 16 careers functioning across the 256 GPUs, a completely scheduled cloth effects in a 1.9x quicker JCT.

Studying the data yet another way, if we check the quantity of precedence movement control (PFC) sent from the network to the GPU, we see that 5% of the GPUs slow down the remaining 95% of the GPUs. In comparison, a thoroughly scheduled cloth offers entirely non-blocking effectiveness, and the community under no circumstances pauses the GPU.

This signifies that for the exact same community, you can link two times as several GPUs for the same dimensions community with absolutely scheduled material. The intention of telemetry assisted Ethernet is to increase the functionality of normal Ethernet by signaling congestion and improving upon load balancing selections.
As I stated before, the relative merits of many technologies range by each shopper and are very likely not consistent in excess of time. I think Ethernet, or telemetry assisted Ethernet, even though decrease effectiveness than fully scheduled fabrics, are an extremely beneficial engineering and will be deployed greatly in AI/ML networks.
So why would prospects opt for a person know-how around the other?
Consumers who want to enjoy the weighty investment decision, open criteria, and favorable value-bandwidth dynamics of Ethernet should really deploy Ethernet for AI/ML networks. They can enhance the performance by investing in telemetry and minimizing network load via thorough placement of AI work opportunities on the infrastructure.
Shoppers who want to appreciate the entire non-blocking overall performance of an ingress virtual output queue (VOQ), thoroughly scheduled, spray and re-get fabric, resulting in an remarkable 1.9x far better position completion time, really should deploy fully scheduled materials for AI/ML networks. Fully scheduled fabrics are also fantastic for buyers who want to preserve cost and power by eradicating network components, but however attain the very same functionality as Ethernet, with 2x far more compute for the similar community.
Cisco Silicon One is uniquely positioned to offer a answer for both of these prospects with a converged architecture and marketplace-main overall performance.

Understand additional:
Study: AI/ML white paper
Stop by: Cisco Silicon A person
Share:
[ad_2]
Supply link