

[ad_1]
Introducing a framework to create AI brokers that can recognize human instructions and complete actions in open-finished configurations
Human conduct is remarkably complex. Even a easy request like, “Set the ball near to the box” continue to needs deep being familiar with of positioned intent and language. The which means of a phrase like ‘close’ can be tricky to pin down – positioning the ball within the box may technically be the closest, but it’s probably the speaker wants the ball placed following to the box. For a man or woman to effectively act on the ask for, they need to be in a position to recognize and choose the situation and encompassing context.
Most synthetic intelligence (AI) scientists now feel that producing laptop code which can seize the nuances of located interactions is impossible. Alternatively, present day machine discovering (ML) researchers have centered on mastering about these styles of interactions from info. To explore these mastering-based strategies and promptly develop agents that can make perception of human recommendations and properly conduct steps in open up-ended disorders, we developed a investigate framework inside of a movie sport ecosystem.
Nowadays, we’re publishing a paper and selection of videos, exhibiting our early steps in setting up online video recreation AIs that can realize fuzzy human ideas – and consequently, can begin to interact with folks on their own conditions.
Substantially of the current development in coaching movie recreation AI relies on optimising the rating of a game. Powerful AI brokers for StarCraft and Dota have been experienced working with the crystal clear-reduce wins/losses calculated by laptop code. Alternatively of optimising a match rating, we question people today to invent duties and choose progress themselves.
Working with this strategy, we created a exploration paradigm that enables us to strengthen agent behaviour via grounded and open up-finished conversation with individuals. Although nevertheless in its infancy, this paradigm generates agents that can hear, discuss, inquire issues, navigate, research and retrieve, manipulate objects, and complete many other routines in real-time.
This compilation shows behaviours of agents pursuing responsibilities posed by human participants:

Finding out in “the playhouse”
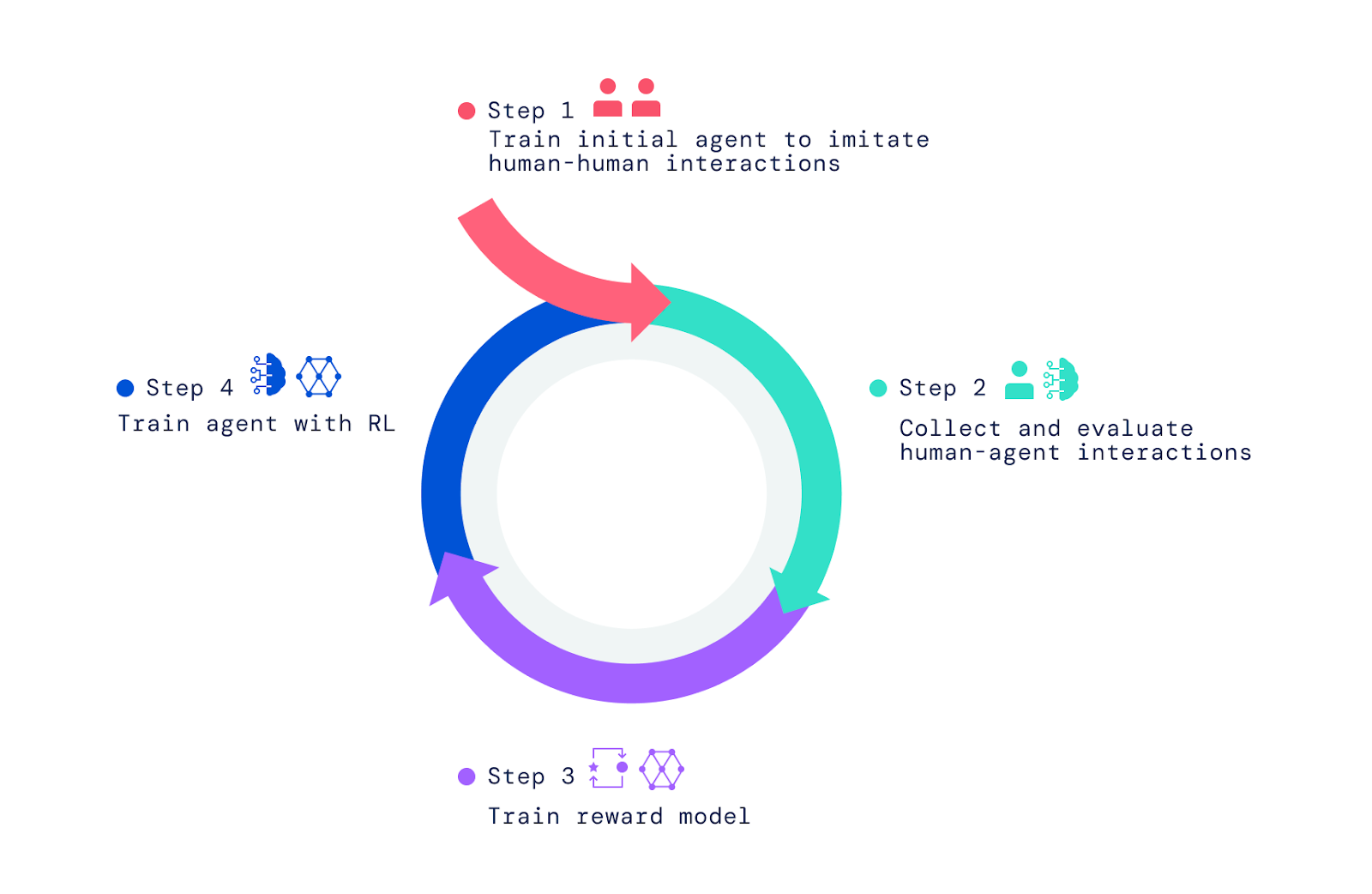
Our framework commences with persons interacting with other people today in the movie match world. Working with imitation understanding, we imbued agents with a broad but unrefined set of behaviours. This “conduct prior” is essential for enabling interactions that can be judged by people. Without having this initial imitation period, agents are fully random and pretty much difficult to interact with. Additional human judgement of the agent’s behaviour and optimisation of these judgements by reinforcement studying (RL) produces greater brokers, which can then be enhanced yet again.
First we designed a simple video clip video game world primarily based on the principle of a kid’s “playhouse.” This setting furnished a safe setting for people and brokers to interact and created it quick to speedily accumulate large volumes of these conversation info. The residence showcased a selection of rooms, home furnishings, and objects configured in new preparations for every interaction. We also produced an interface for interaction.
Each the human and agent have an avatar in the activity that permits them to transfer in – and manipulate – the natural environment. They can also chat with each individual other in authentic-time and collaborate on pursuits, such as carrying objects and handing them to every other, creating a tower of blocks, or cleansing a area collectively. Human participants established the contexts for the interactions by navigating by the planet, placing targets, and asking concerns for agents. In full, the job gathered extra than 25 decades of actual-time interactions concerning agents and hundreds of (human) individuals.
Observing behaviours that arise
The agents we experienced are capable of a big variety of duties, some of which have been not predicted by the researchers who crafted them. For instance, we uncovered that these agents can construct rows of objects making use of two alternating colours or retrieve an object from a property that is equivalent to a different item the user is holding.
These surprises emerge for the reason that language permits a practically infinite established of responsibilities and concerns by way of the composition of straightforward meanings. Also, as researchers, we do not specify the particulars of agent behaviour. Alternatively, the hundreds of individuals who have interaction in interactions came up with responsibilities and thoughts during the course of these interactions.
Creating the framework for developing these agents
To produce our AI agents, we used a few methods. We started out by coaching agents to imitate the primary things of basic human interactions in which one particular person asks an additional to do a thing or to response a question. We refer to this stage as producing a behavioural prior that permits agents to have meaningful interactions with a human with superior frequency. Without this imitative section, brokers just transfer randomly and communicate nonsense. They’re practically extremely hard to interact with in any fair style and supplying them opinions is even much more tricky. This section was protected in two of our earlier papers, Imitating Interactive Intelligence, and Producing Multimodal Interactive Brokers with Imitation and Self-Supervised Finding out, which explored creating imitation-primarily based brokers.
Shifting further than imitation understanding
Although imitation studying prospects to attention-grabbing interactions, it treats each moment of interaction as equally important. To learn effective, intention-directed behaviour, an agent needs to pursue an aim and master distinct movements and decisions at crucial times. For instance, imitation-dependent agents do not reliably consider shortcuts or complete jobs with increased dexterity than an normal human participant.
Here we display an imitation-understanding based mostly agent and an RL-based mostly agent pursuing the similar human instruction:
To endow our agents with a feeling of intent, surpassing what’s feasible via imitation, we relied on RL, which employs trial and mistake blended with a measure of general performance for iterative improvement. As our brokers tried out various steps, individuals that enhanced overall performance ended up strengthened, whilst all those that diminished effectiveness were penalised.
In game titles like Atari, Dota, Go, and StarCraft, the score supplies a efficiency measure to be enhanced. Rather of making use of a score, we questioned human beings to assess situations and supply comments, which helped our agents learn a design of reward.
Schooling the reward product and optimising agents
To teach a reward product, we questioned human beings to decide if they observed events indicating conspicuous progress toward the current instructed purpose or conspicuous errors or faults. We then drew a correspondence involving these optimistic and damaging functions and beneficial and destructive preferences. Considering that they get area throughout time, we connect with these judgements “inter-temporal.” We properly trained a neural community to forecast these human choices and attained as a final result a reward (or utility / scoring) product reflecting human feedback.
The moment we qualified the reward product utilizing human tastes, we used it to optimise agents. We placed our agents into the simulator and directed them to remedy thoughts and adhere to instructions. As they acted and spoke in the atmosphere, our trained reward model scored their conduct, and we utilised an RL algorithm to optimise agent efficiency.
So in which do the job instructions and queries come from? We explored two techniques for this. 1st, we recycled the duties and concerns posed in our human dataset. Next, we experienced agents to mimic how people established tasks and pose questions, as proven in this online video, the place two agents, 1 educated to mimic people environment tasks and posing concerns (blue) and one particular trained to stick to guidelines and solution issues (yellow), interact with every single other:
Evaluating and iterating to continue increasing brokers
We used a wide variety of unbiased mechanisms to examine our agents, from hand-scripted assessments to a new mechanism for offline human scoring of open up-ended jobs established by people today, made in our former perform Evaluating Multimodal Interactive Agents. Importantly, we requested folks to interact with our brokers in true-time and judge their effectiveness. Our agents skilled by RL done considerably greater than people trained by imitation understanding alone.
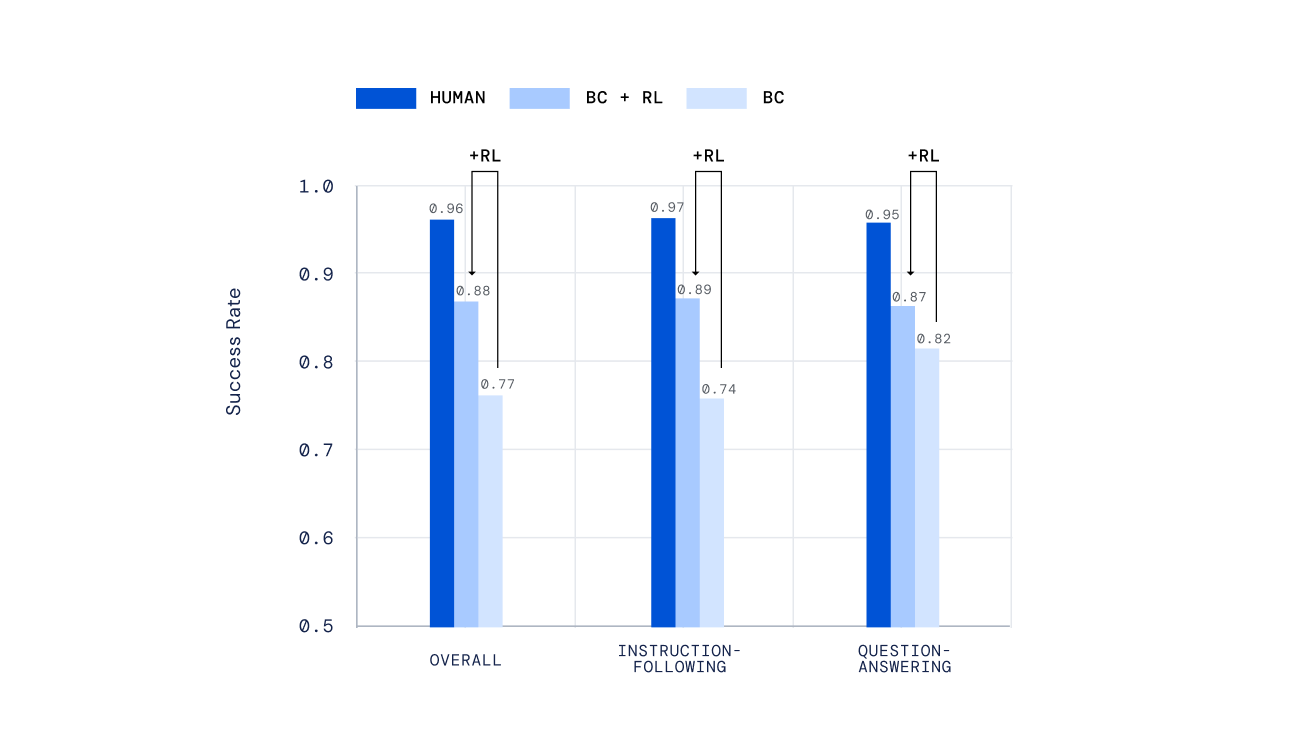
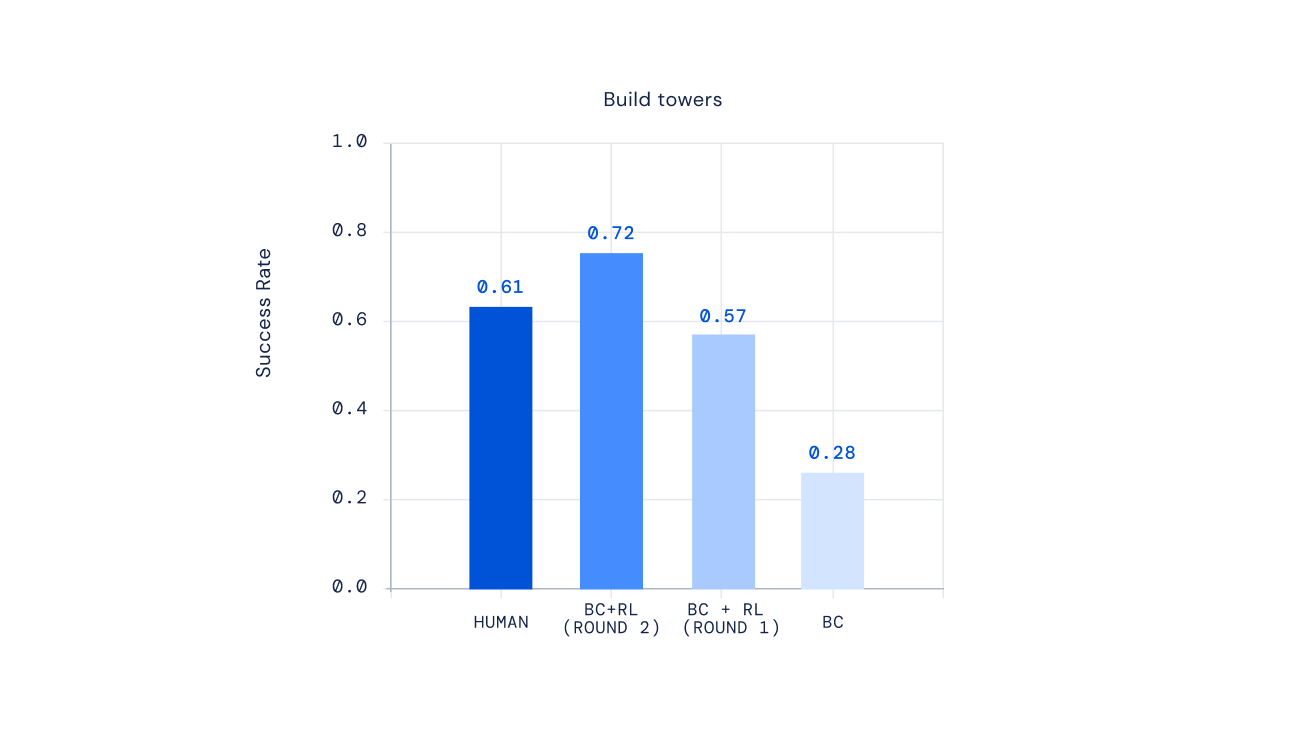
Lastly, recent experiments display we can iterate the RL system to continuously strengthen agent conduct. At the time an agent is trained by way of RL, we asked individuals to interact with this new agent, annotate its behaviour, update our reward model, and then conduct an additional iteration of RL. The result of this approach was progressively proficient brokers. For some varieties of complicated directions, we could even make brokers that outperformed human players on average.
The long term of coaching AI for positioned human preferences
The strategy of training AI applying human choices as a reward has been all around for a long time. In Deep reinforcement learning from human tastes, scientists pioneered new techniques to aligning neural community primarily based agents with human preferences. Current work to create transform-centered dialogue brokers explored very similar strategies for schooling assistants with RL from human suggestions. Our study has adapted and expanded these concepts to make adaptable AIs that can learn a broad scope of multi-modal, embodied, true-time interactions with people today.
We hope our framework may well someday lead to the generation of activity AIs that are capable of responding to our normally expressed meanings, somewhat than relying on hand-scripted behavioural plans. Our framework could also be beneficial for building digital and robotic assistants for men and women to interact with just about every day. We appear forward to exploring the probability of making use of features of this framework to create risk-free AI that is definitely handy.
Thrilled to study much more? Verify out our most recent paper. Opinions and responses are welcome.
[ad_2]
Source backlink