
[ad_1]

As digital assistants grow to be ubiquitous, users significantly interact with them to study about new subject areas or get tips and count on them to supply abilities outside of narrow dialogues of just one or two turns. Dynamic organizing, specifically the functionality to search ahead and replan based mostly on the move of the discussion, is an important component for the generating of participating discussions with the deeper, open up-ended interactions that buyers count on.
Whilst big language products (LLMs) are now beating point out-of-the-art strategies in a lot of organic language processing benchmarks, they are usually trained to output the following finest reaction, rather than planning in advance, which is expected for multi-switch interactions. Nevertheless, in the previous couple of several years, reinforcement studying (RL) has shipped unbelievable outcomes addressing unique challenges that contain dynamic preparing, this kind of as successful video games and protein folding.
Nowadays, we are sharing our recent innovations in dynamic setting up for human-to-assistant discussions, in which we allow an assistant to plan a multi-convert dialogue in direction of a aim and adapt that system in genuine-time by adopting an RL-centered method. In this article we search at how to make improvements to lengthy interactions by applying RL to compose solutions based on info extracted from reliable sources, instead than relying on written content produced by a language model. We anticipate that long run versions of this do the job could merge LLMs and RL in multi-change dialogues. The deployment of RL “in the wild” in a large-scale dialogue process proved a formidable challenge owing to the modeling complexity, tremendously huge condition and motion spaces, and important subtlety in designing reward capabilities.
What is dynamic setting up?
Several kinds of conversations, from gathering information and facts to presenting suggestions, require a flexible solution and the ability to modify the original program for the dialogue based mostly on its circulation. This capability to shift gears in the center of a discussion is known as dynamic arranging, as opposed to static scheduling, which refers to a more mounted tactic. In the conversation below, for case in point, the purpose is to engage the user by sharing exciting info about interesting animals. To get started, the assistant steers the dialogue to sharks by means of a seem quiz. Provided the user’s absence of curiosity in sharks, the assistant then develops an current strategy and pivots the conversation to sea lions, lions, and then cheetahs.
 |
| The assistant dynamically modifies its original strategy to converse about sharks and shares information about other animals. |
Dynamic composition
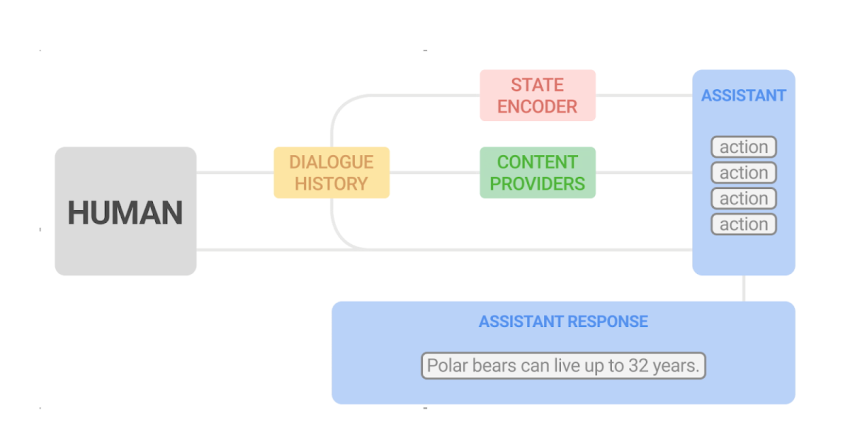
To cope with the challenge of conversational exploration, we different the era of assistant responses into two parts: 1) written content technology, which extracts appropriate information and facts from reputable sources, and 2) flexible composition of this kind of information into assistant responses. We refer to this two-part technique as dynamic composition. Compared with LLM procedures, this method presents the assistant the means to fully handle the resource, correctness, and quality of the material that it may well give. At the identical time, it can obtain flexibility by means of a discovered dialogue manager that selects and combines the most suitable written content.
In an previously paper, “Dynamic Composition for Conversational Domain Exploration”, we explain a novel tactic which is made up of: (1) a assortment of information vendors, which offer candidates from unique sources, these kinds of as news snippets, awareness graph facts, and inquiries (2) a dialogue manager and (3) a sentence fusion module. Just about every assistant reaction is incrementally made by the dialogue supervisor, which selects candidates proposed by the content suppliers. The picked sequence of utterances is then fused into a cohesive reaction.
Dynamic setting up working with RL
At the core of the assistant response composition loop is a dialogue supervisor properly trained making use of off-coverage RL, specifically an algorithm that evaluates and enhances a coverage that is unique from the policy utilized by the agent (in our case, the latter is primarily based on a supervised model). Making use of RL to dialogue administration offers numerous difficulties, such as a substantial state space (as the point out represents the discussion state, which demands to account for the whole dialogue historical past) and an proficiently unbounded action room (that may perhaps consist of all current words or sentences in natural language).
We tackle these worries applying a novel RL building. First, we leverage highly effective supervised models — particularly, recurrent neural networks (RNNs) and transformers — to give a succinct and powerful dialogue condition illustration. These point out encoders are fed with the dialogue historical past, composed of a sequence of consumer and assistant turns, and output a representation of the dialogue point out in the variety of a latent vector.
Next, we use the fact that a reasonably little set of reasonable prospect utterances or actions can be generated by articles companies at each individual conversation convert, and restrict the action place to these. Whereas the motion place is usually fixed in RL settings, because all states share the identical motion house, ours is a non-typical space in which the candidate actions might differ with each and every state, due to the fact information providers generate different steps based on the dialogue context. This puts us in the realm of stochastic action sets, a framework that formalizes instances where by the established of actions readily available in each and every condition is governed by an exogenous stochastic procedure, which we deal with making use of Stochastic Motion Q-Learning, a variant of the Q-studying technique. Q-mastering is a common off-plan RL algorithm, which does not call for a model of the setting to examine and enhance the policy. We trained our design on a corpus of group-compute–rated conversations acquired utilizing a supervised dialogue supervisor.
 |
| Supplied the current dialogue historical past and a new consumer question, material companies generate candidates from which the assistant selects just one. This system runs in a loop, and at the stop the chosen utterances are fused into a cohesive reaction. |
Reinforcement finding out design analysis
We compared our RL dialogue manager with a launched supervised transformer product in an experiment utilizing Google Assistant, which conversed with users about animals. A conversation starts when a person triggers the expertise by inquiring an animal-connected question (e.g., “How does a lion seem?”). The experiment was performed using an A/B screening protocol, in which a modest percentage of Assistant users had been randomly sampled to interact with our RL-based assistant though other users interacted with the typical assistant.
We found that the RL dialogue supervisor conducts more time, extra engaging conversations. It increases dialogue size by 30% when enhancing user engagement metrics. We see an increase of 8% in cooperative responses to the assistant’s queries — e.g., “Tell me about lions,” in response to “Which animal do you want to listen to about next?” Despite the fact that there is also a huge increase in nominally “non-cooperative” responses (e.g., “No,” as a reply to a query proposing extra information, this sort of as “Do you want to listen to extra?”), this is envisioned as the RL agent usually takes much more challenges by asking pivoting questions. Even though a user may well not be fascinated in the conversational route proposed by the assistant (e.g., pivoting to yet another animal), the user will normally go on to interact in a dialogue about animals.
 |
| From the non-cooperative user reaction in the 3rd change (“No.”) and the query “Make a dog sound,” in the 5th flip, the assistant acknowledges that the person is largely intrigued in animal seems and modifies its approach, supplying seems and audio quizzes. |
In addition, some consumer queries comprise specific beneficial (e.g., “Thank you, Google,” or “I’m happy.”) or detrimental (e.g., “Shut up,” or “Stop.”) feedback. While an purchase of magnitude much less than other queries, they offer a direct evaluate of user (dis)fulfillment. The RL design raises specific positive feedback by 32% and lessens adverse feedback by 18%.
Acquired dynamic planning qualities and procedures
We notice a number of attributes of the (unseen) RL system to enhance person engagement although conducting more time conversations. 1st, the RL-based mostly assistant ends 20% additional turns in questions, prompting the person to opt for more content material. It also better harnesses information variety, such as information, seems, quizzes, yes/no issues, open up thoughts, etcetera. On common, the RL assistant works by using 26% additional distinct written content companies for each discussion than the supervised model.
Two noticed RL arranging methods are relevant to the existence of sub-dialogues with various qualities. Sub-dialogues about animal seems are poorer in written content and exhibit entity pivoting at each individual change (i.e., just after playing the sound of a provided animal, we can either counsel the sound of a diverse animal or quiz the person about other animal appears). In contrast, sub-dialogues involving animal information normally contain richer information and have larger conversation depth. We notice that RL favors the richer knowledge of the latter, selecting 31% more truth-associated articles. Last of all, when restricting evaluation to actuality-relevant dialogues, the RL assistant reveals 60% far more concentrate-pivoting turns, that is, conversational turns that modify the emphasis of the dialogue.
Underneath, we clearly show two illustration discussions, 1 performed by the supervised design (remaining) and the second by the RL product (correct), in which the initially a few consumer turns are equivalent. With a supervised dialogue supervisor, just after the user declined to hear about “today’s animal”, the assistant pivots back again to animal sounds to increase the fast consumer pleasure. While the discussion carried out by the RL product starts identically, it exhibits a distinctive planning technique to enhance the overall consumer engagement, introducing much more assorted articles, this kind of as pleasurable details.
 |
| In the still left dialogue, executed by the supervised design, the assistant maximizes the speedy user pleasure. The proper conversation, carried out by the RL design, shows various preparing tactics to improve the in general person engagement. |
Long run analysis and issues
In the past couple years, LLMs properly trained for language understanding and era have shown impressive effects across many duties, which include dialogue. We are now checking out the use of an RL framework to empower LLMs with the ability of dynamic organizing so that they can dynamically prepare in advance and delight buyers with a extra participating expertise.
Acknowledgements
The perform explained is co-authored by: Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor and Gal Elidan. We would like to thank: Roee Aharoni, Moran Ambar, John Anderson, Ido Cohn, Mohammad Ghavamzadeh, Lotem Golany, Ziv Hodak, Adva Levin, Fernando Pereira, Shimi Salant, Shachar Shimoni, Ronit Slyper, Ariel Stolovich, Hagai Taitelbaum, Noam Velan, Avital Zipori and the CrowdCompute crew led by Ashwin Kakarla. We thank Sophie Allweis for her opinions on this blogpost and Tom Tiny for the visualization.
[ad_2]
Resource backlink