
[ad_1]
New, formal definition of company provides crystal clear ideas for causal modelling of AI agents and the incentives they experience
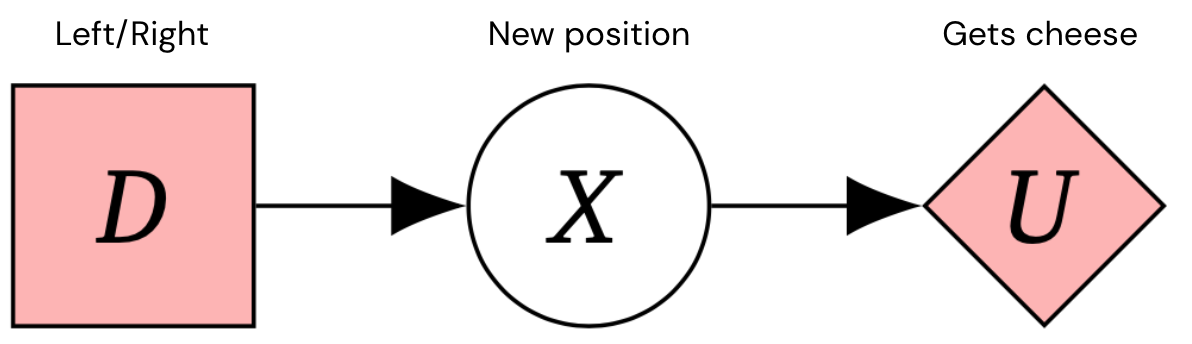
We want to establish protected, aligned synthetic typical intelligence (AGI) devices that pursue the intended aims of its designers. Causal impact diagrams (CIDs) are a way to design conclusion-earning predicaments that allow us to explanation about agent incentives. For illustration, here is a CID for a 1-stage Markov conclusion system – a regular framework for conclusion-generating problems.

By relating teaching setups to the incentives that form agent conduct, CIDs assistance illuminate probable dangers right before schooling an agent and can inspire superior agent models. But how do we know when a CID is an accurate model of a education setup?
Our new paper, Finding Brokers, introduces new approaches of tackling these difficulties, such as:
- The to start with official causal definition of agents: Agents are systems that would adapt their policy if their steps motivated the earth in a unique way
- An algorithm for discovering agents from empirical data
- A translation concerning causal designs and CIDs
- Resolving previously confusions from incorrect causal modelling of brokers
Mixed, these final results offer an further layer of assurance that a modelling miscalculation has not been created, which indicates that CIDs can be utilised to analyse an agent’s incentives and basic safety attributes with better self-assurance.
Case in point: modelling a mouse as an agent
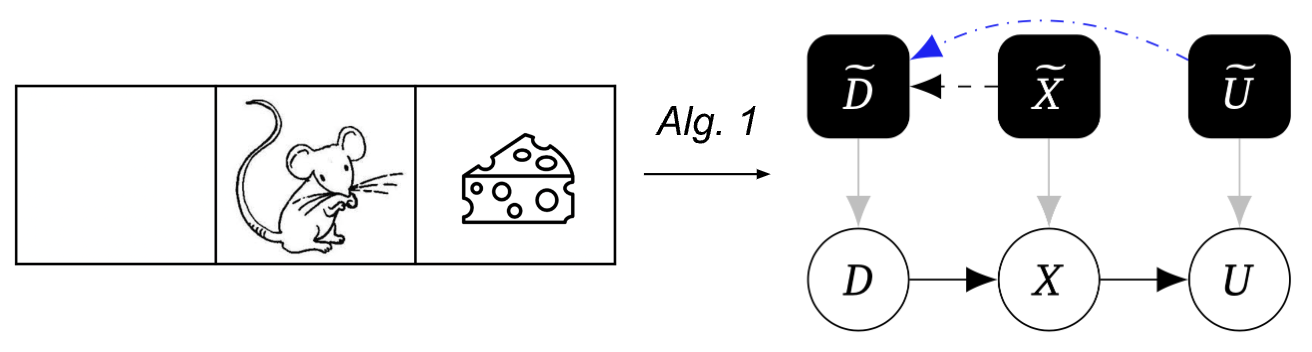
To support illustrate our process, consider the subsequent case in point consisting of a entire world that contains a few squares, with a mouse beginning in the middle sq. selecting to go still left or correct, acquiring to its up coming position and then probably having some cheese. The ground is icy, so the mouse could slip. From time to time the cheese is on the appropriate, but sometimes on the remaining.

This can be represented by the adhering to CID:
The instinct that the mouse would decide on a distinct behaviour for unique atmosphere options (iciness, cheese distribution) can be captured by a mechanised causal graph, which for every single (item-stage) variable, also incorporates a mechanism variable that governs how the variable is dependent on its parents. Crucially, we enable for backlinks concerning mechanism variables.
This graph has additional mechanism nodes in black, symbolizing the mouse’s policy and the iciness and cheese distribution.
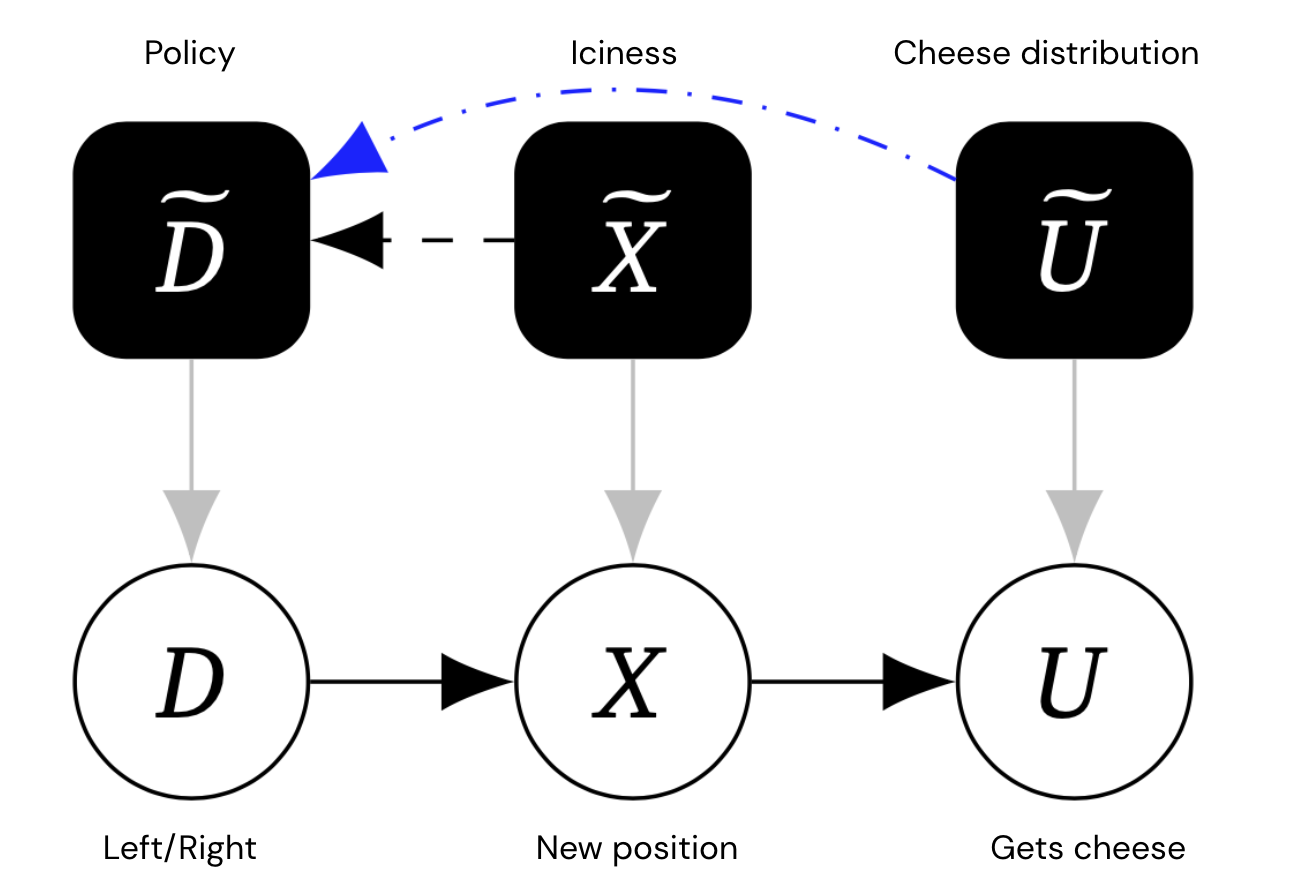
Edges concerning mechanisms depict direct causal influence. The blue edges are exclusive terminal edges – approximately, system edges A~ → B~ that would continue to be there, even if the object-amount variable A was altered so that it experienced no outgoing edges.
In the illustration over, due to the fact U has no youngsters, its system edge should be terminal. But the system edge X~ → D~ is not terminal, simply because if we slash X off from its boy or girl U, then the mouse will no extended adapt its selection (mainly because its posture will not influence whether or not it gets the cheese).
Causal discovery of agents
Causal discovery infers a causal graph from experiments involving interventions. In certain, one particular can find an arrow from a variable A to a variable B by experimentally intervening on A and examining if B responds, even if all other variables are held preset.
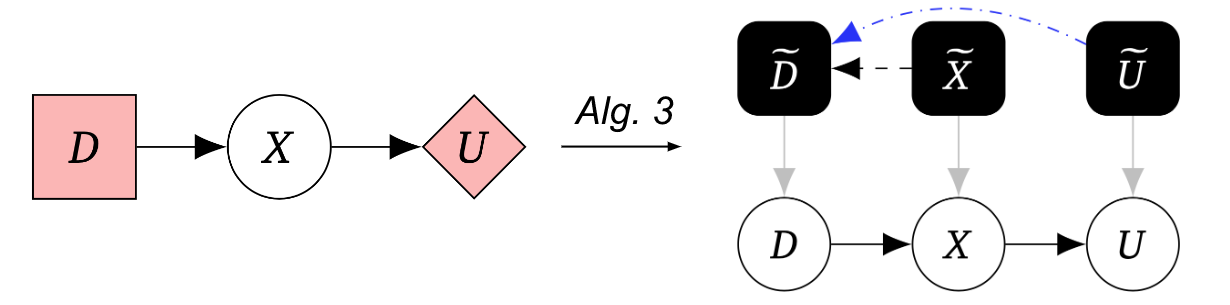
Our to start with algorithm uses this procedure to discover the mechanised causal graph:
Our 2nd algorithm transforms this mechanised causal graph to a sport graph:
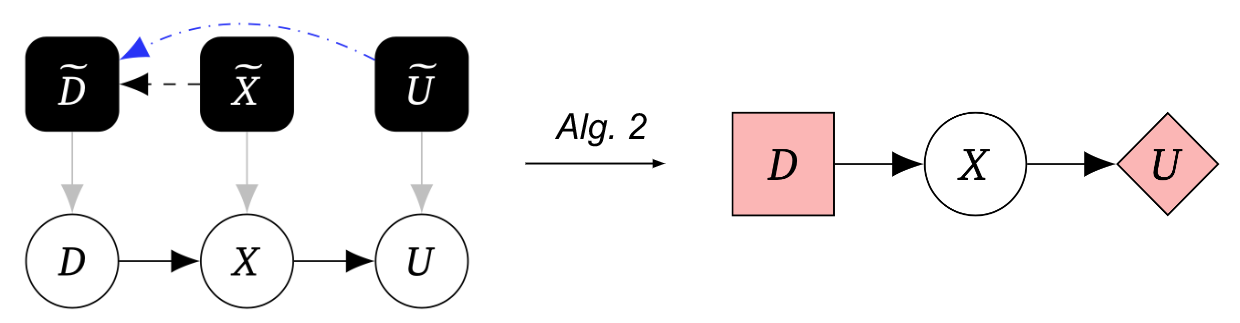
Taken jointly, Algorithm 1 adopted by Algorithm 2 permits us to uncover agents from causal experiments, symbolizing them making use of CIDs.
Our 3rd algorithm transforms the game graph into a mechanised causal graph, allowing for us to translate involving the sport and mechanised causal graph representations beneath some added assumptions:
Better basic safety instruments to design AI agents
We proposed the very first formal causal definition of brokers. Grounded in causal discovery, our crucial insight is that brokers are units that adapt their conduct in response to changes in how their actions affect the globe. In truth, our Algorithms 1 and 2 describe a exact experimental approach that can support evaluate irrespective of whether a program has an agent.
Desire in causal modelling of AI systems is promptly developing, and our exploration grounds this modelling in causal discovery experiments. Our paper demonstrates the likely of our tactic by increasing the safety analysis of several example AI systems and exhibits that causality is a helpful framework for identifying whether or not there is an agent in a procedure – a key issue for evaluating challenges from AGI.
Psyched to master extra? Check out out our paper. Feed-back and reviews are most welcome.
[ad_2]
Supply url