

[ad_1]
MLPerf remains the definitive measurement for AI effectiveness as an unbiased, 3rd-occasion benchmark. NVIDIA’s AI system has persistently shown management across equally teaching and inference considering the fact that the inception of MLPerf, like the MLPerf Inference 3. benchmarks unveiled now.
“Three years ago when we introduced A100, the AI entire world was dominated by computer vision. Generative AI has arrived,” explained NVIDIA founder and CEO Jensen Huang.
“This is just why we created Hopper, precisely optimized for GPT with the Transformer Motor. Today’s MLPerf 3. highlights Hopper providing 4x more effectiveness than A100.
“The up coming degree of Generative AI necessitates new AI infrastructure to practice substantial language designs with good vitality effectiveness. Buyers are ramping Hopper at scale, creating AI infrastructure with tens of 1000’s of Hopper GPUs linked by NVIDIA NVLink and InfiniBand.
“The field is doing work tough on new innovations in safe and honest Generative AI. Hopper is enabling this critical perform,” he reported.
The most up-to-date MLPerf benefits clearly show NVIDIA using AI inference to new concentrations of general performance and performance from the cloud to the edge.
Exclusively, NVIDIA H100 Tensor Core GPUs managing in DGX H100 techniques sent the maximum overall performance in each individual exam of AI inference, the position of operating neural networks in manufacturing. Thanks to computer software optimizations, the GPUs sent up to 54% effectiveness gains from their debut in September.
In healthcare, H100 GPUs shipped a 31% overall performance enhance considering the fact that September on 3D-UNet, the MLPerf benchmark for health care imaging.
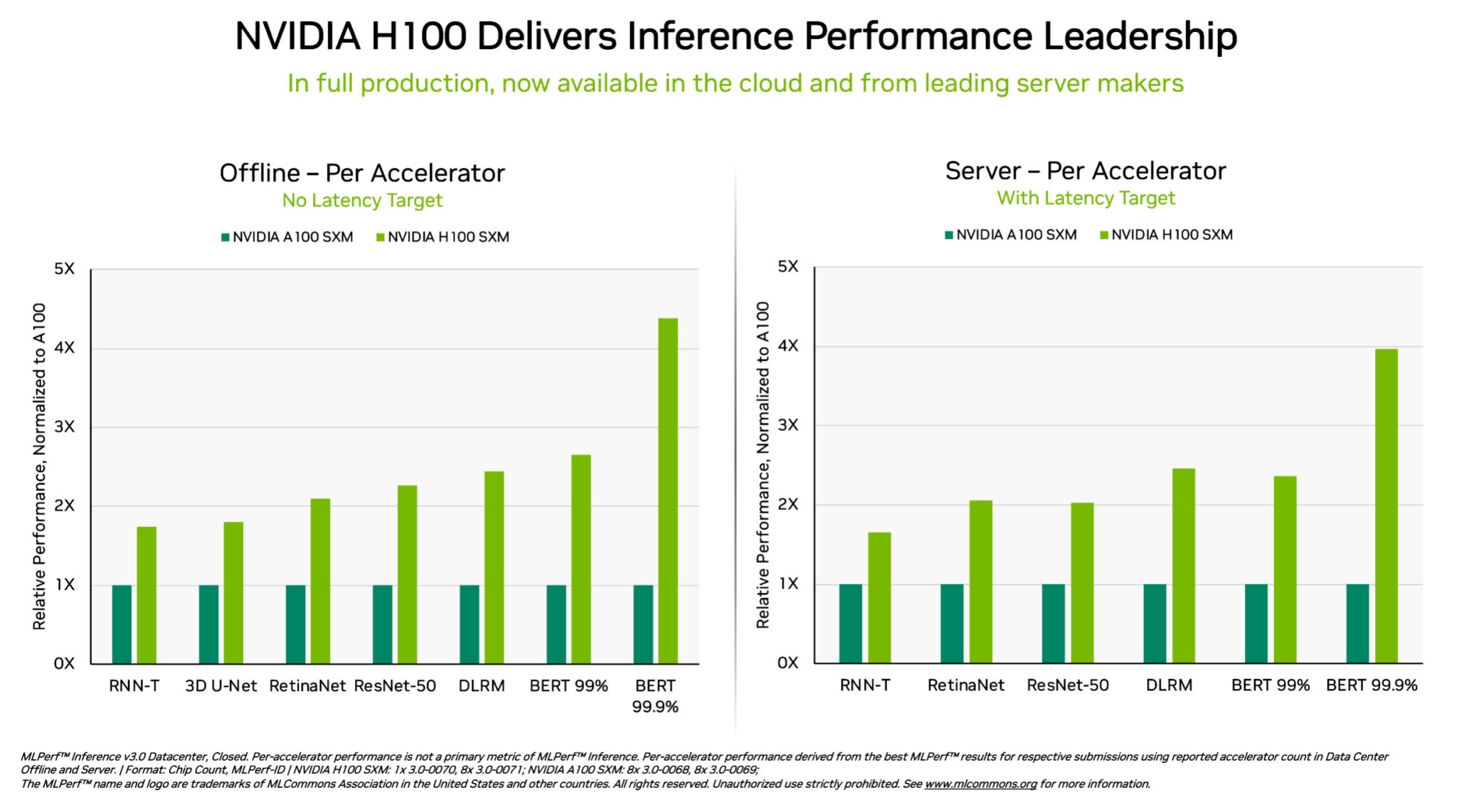
Powered by its Transformer Engine, the H100 GPU, primarily based on the Hopper architecture, excelled on BERT, a transformer-based mostly large language model that paved the way for today’s wide use of generative AI.
Generative AI lets customers immediately make textual content, pictures, 3D versions and additional. It is a capability firms from startups to cloud service providers are swiftly adopting to allow new small business models and speed up present ones.
Hundreds of hundreds of thousands of folks are now applying generative AI applications like ChatGPT — also a transformer design — expecting instantaneous responses.
At this Apple iphone minute of AI, efficiency on inference is vital. Deep mastering is now staying deployed virtually just about everywhere, driving an insatiable have to have for inference efficiency from factory flooring to on the internet suggestion programs.
L4 GPUs Velocity Out of the Gate
NVIDIA L4 Tensor Main GPUs designed their debut in the MLPerf checks at about 3x the velocity of prior-generation T4 GPUs. Packaged in a very low-profile kind variable, these accelerators are built to deliver significant throughput and very low latency in nearly any server.
L4 GPUs ran all MLPerf workloads. Thanks to their support for the vital FP8 structure, their results were being specially amazing on the general performance-hungry BERT product.
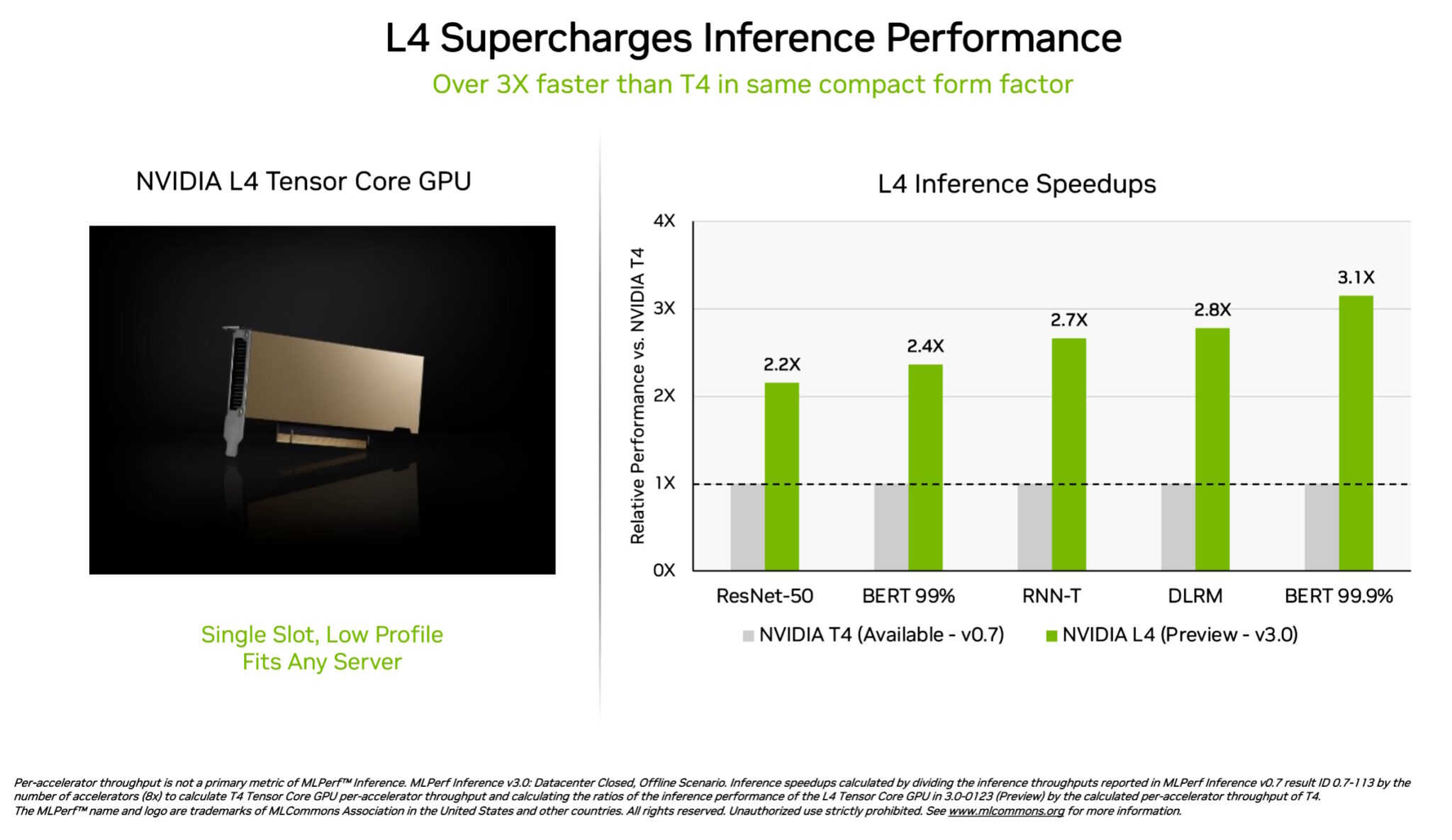
In addition to stellar AI performance, L4 GPUs supply up to 10x faster graphic decode, up to 3.2x more quickly video processing and in excess of 4x a lot quicker graphics and serious-time rendering functionality.
Introduced two months ago at GTC, these accelerators are already accessible from main devices makers and cloud company suppliers. L4 GPUs are the newest addition to NVIDIA’s portfolio of AI inference platforms launched at GTC.
Software, Networks Glow in Technique Examination
NVIDIA’s full-stack AI system confirmed its leadership in a new MLPerf take a look at.
The so-termed network-division benchmark streams knowledge to a remote inference server. It reflects the common circumstance of enterprise buyers operating AI careers in the cloud with info stored behind company firewalls.
On BERT, remote NVIDIA DGX A100 programs delivered up to 96% of their highest nearby effectiveness, slowed in component for the reason that they necessary to hold out for CPUs to full some responsibilities. On the ResNet-50 test for personal computer vision, taken care of solely by GPUs, they hit the comprehensive 100%.
Both equally benefits are many thanks, in substantial part, to NVIDIA Quantum Infiniband networking, NVIDIA ConnectX SmartNICs and software program this sort of as NVIDIA GPUDirect.
Orin Shows 3.2x Gains at the Edge
Separately, the NVIDIA Jetson AGX Orin program-on-module sent gains of up to 63% in energy performance and 81% in effectiveness in comparison with its benefits a year ago. Jetson AGX Orin materials inference when AI is required in confined areas at very low power degrees, like on devices run by batteries.
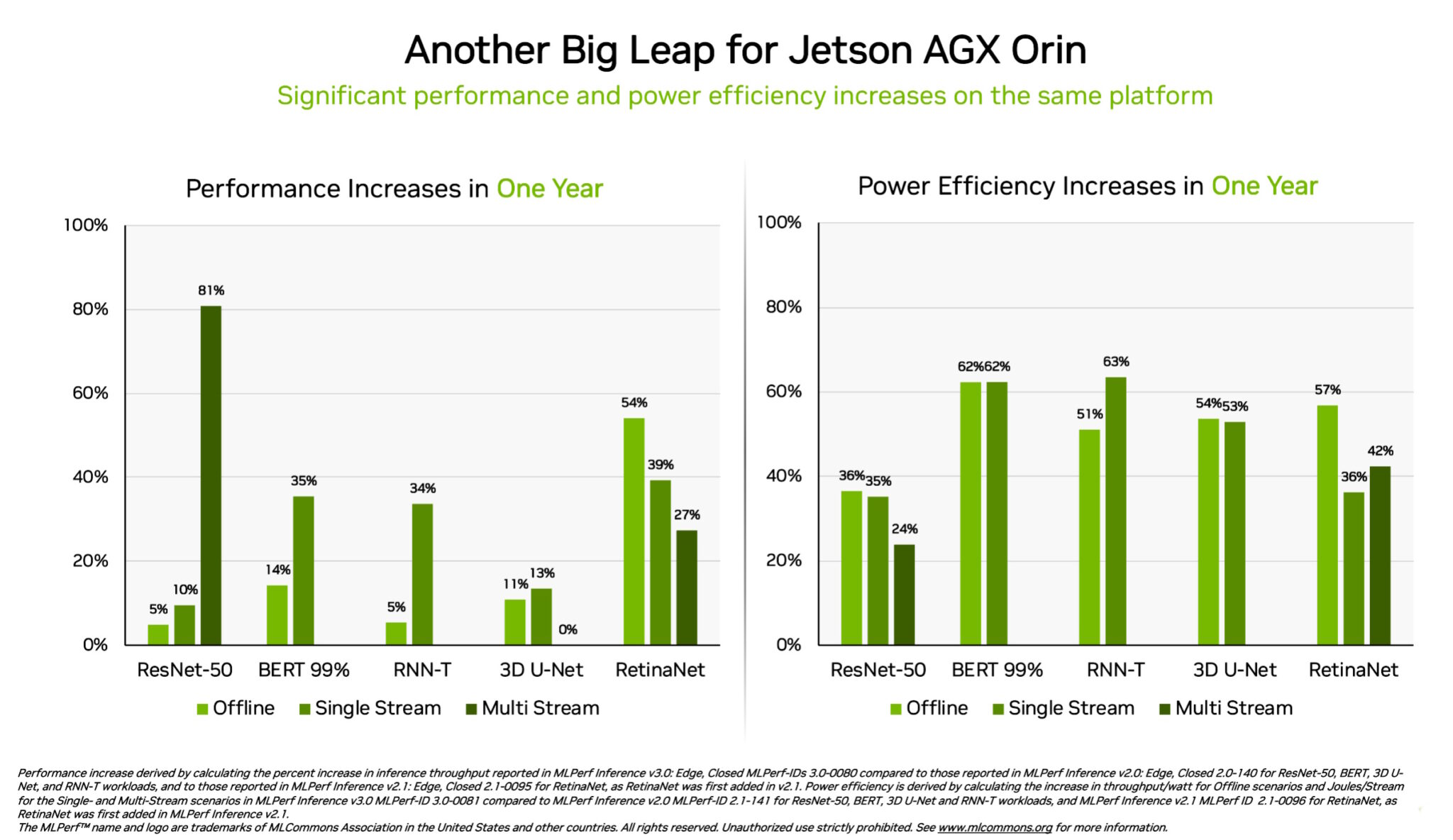
For purposes needing even smaller sized modules drawing a lot less electricity, the Jetson Orin NX 16G shined in its debut in the benchmarks. It delivered up to 3.2x the general performance of the prior-technology Jetson Xavier NX processor.
A Broad NVIDIA AI Ecosystem
The MLPerf success show NVIDIA AI is backed by the industry’s broadest ecosystem in equipment studying.
Ten providers submitted final results on the NVIDIA system in this round. They came from the Microsoft Azure cloud service and program makers which include ASUS, Dell Technologies, GIGABYTE, H3C, Lenovo, Nettrix, Supermicro and xFusion.
Their get the job done exhibits buyers can get excellent efficiency with NVIDIA AI the two in the cloud and in servers functioning in their have data facilities.
NVIDIA partners take part in MLPerf since they know it is a precious instrument for consumers analyzing AI platforms and suppliers. Final results in the latest spherical show that the efficiency they supply now will develop with the NVIDIA system.
Consumers Want Functional Efficiency
NVIDIA AI is the only system to operate all MLPerf inference workloads and eventualities in details middle and edge computing. Its adaptable overall performance and effectiveness make consumers the serious winners.
Genuine-globe purposes usually utilize numerous neural networks of distinctive varieties that normally need to have to produce solutions in actual time.
For case in point, an AI software could need to have to understand a user’s spoken ask for, classify an image, make a recommendation and then provide a reaction as a spoken message in a human-sounding voice. Every stage involves a various form of AI design.
The MLPerf benchmarks address these and other preferred AI workloads. Which is why the assessments assure IT decision makers will get performance which is reliable and flexible to deploy.
End users can count on MLPerf final results to make educated buying selections, mainly because the assessments are clear and goal. The benchmarks take pleasure in backing from a wide group that includes Arm, Baidu, Facebook AI, Google, Harvard, Intel, Microsoft, Stanford and the University of Toronto.
Software You Can Use
The computer software layer of the NVIDIA AI platform, NVIDIA AI Enterprise, ensures buyers get optimized overall performance from their infrastructure investments as perfectly as the company-grade support, protection and dependability necessary to run AI in the corporate data heart.
All the application utilized for these assessments is offered from the MLPerf repository, so any one can get these planet-course effects.
Optimizations are consistently folded into containers accessible on NGC, NVIDIA’s catalog for GPU-accelerated software package. The catalog hosts NVIDIA TensorRT, applied by each individual submission in this round to optimize AI inference.
Read through this technical blog site for a further dive into the optimizations fueling NVIDIA’s MLPerf effectiveness and performance.
[ad_2]
Resource connection