
[ad_1]
Automated speech recognition (ASR) is a well-established know-how that is commonly adopted for several apps this sort of as convention phone calls, streamed video clip transcription and voice instructions. While the difficulties for this know-how are centered all-around noisy audio inputs, the visible stream in multimodal videos (e.g., Tv set, on the net edited films) can supply solid cues for strengthening the robustness of ASR methods — this is termed audiovisual ASR (AV-ASR).
Despite the fact that lip movement can supply powerful indicators for speech recognition and is the most frequent place of focus for AV-ASR, the mouth is frequently not specifically visible in video clips in the wild (e.g., owing to selfish viewpoints, confront coverings, and very low resolution) and therefore, a new rising area of investigation is unconstrained AV-ASR (e.g., AVATAR), which investigates the contribution of complete visible frames, and not just the mouth region.
Constructing audiovisual datasets for coaching AV-ASR products, even so, is challenging. Datasets this sort of as How2 and VisSpeech have been made from tutorial videos online, but they are modest in dimension. In distinction, the designs them selves are usually large and consist of equally visible and audio encoders, and so they tend to overfit on these small datasets. Even so, there have been a amount of recently released substantial-scale audio-only styles that are greatly optimized through big-scale instruction on significant audio-only details acquired from audio guides, this sort of as LibriLight and LibriSpeech. These styles comprise billions of parameters, are readily obtainable, and demonstrate potent generalization throughout domains.
With the earlier mentioned worries in intellect, in “AVFormer: Injecting Vision into Frozen Speech Versions for Zero-Shot AV-ASR”, we present a easy method for augmenting existing substantial-scale audio-only styles with visual details, at the very same time performing light-weight area adaptation. AVFormer injects visible embeddings into a frozen ASR model (similar to how Flamingo injects visual details into huge language types for vision-text duties) working with light-weight trainable adaptors that can be trained on a small amount of money of weakly labeled video clip information with bare minimum further education time and parameters. We also introduce a very simple curriculum scheme all through teaching, which we demonstrate is important to permit the model to jointly method audio and visual information efficiently. The resulting AVFormer product achieves condition-of-the-artwork zero-shot functionality on 3 distinct AV-ASR benchmarks (How2, VisSpeech and Moi4D), even though also crucially preserving decent functionality on classic audio-only speech recognition benchmarks (i.e., LibriSpeech).
 |
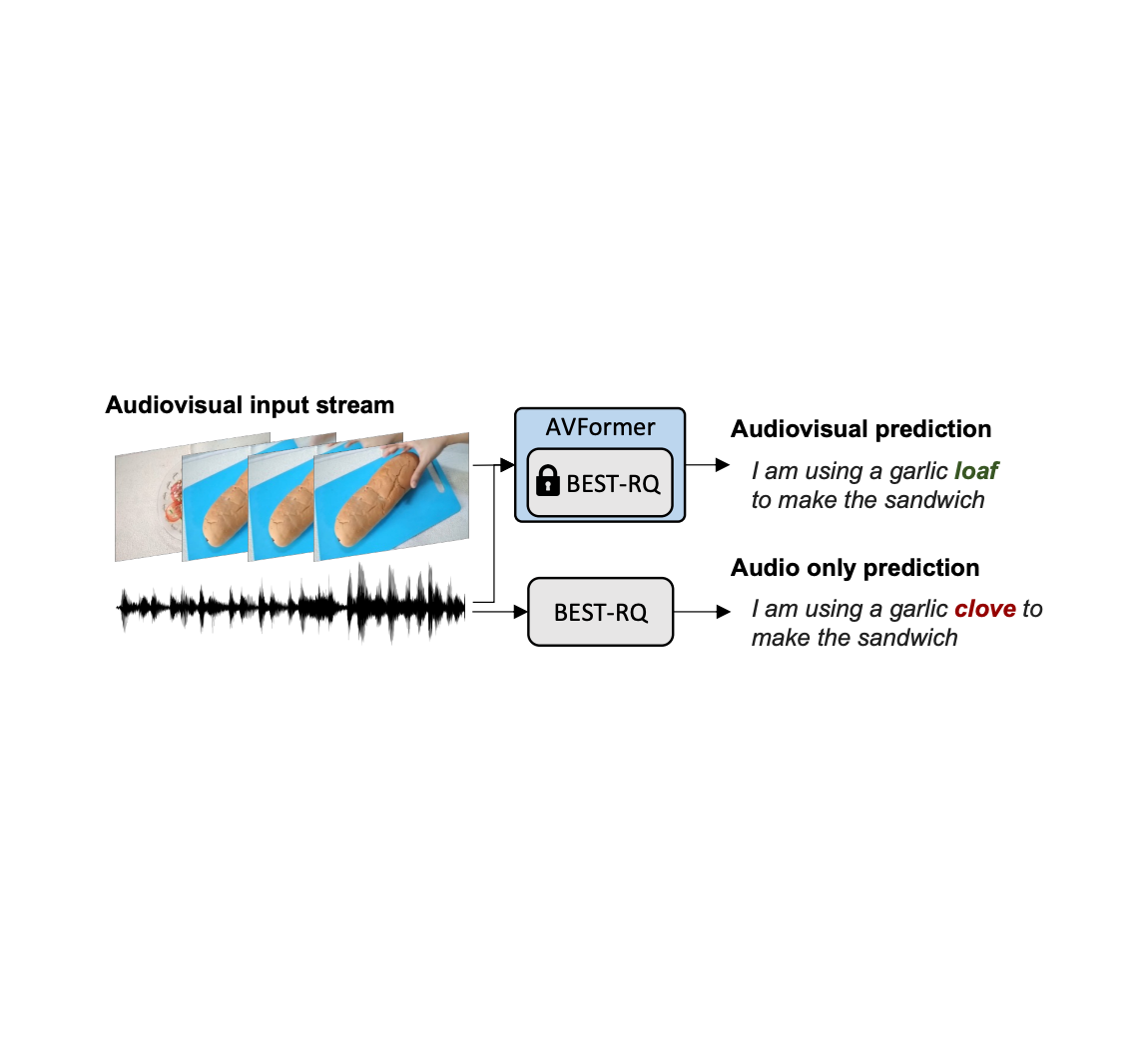
| Unconstrained audiovisual speech recognition. We inject eyesight into a frozen speech model (Very best-RQ, in gray) for zero-shot audiovisual ASR by means of light-weight modules to create a parameter- and info-productive design identified as AVFormer (blue). The visual context can offer valuable clues for strong speech recognition particularly when the audio sign is noisy (the visual loaf of bread helps accurate the audio-only miscalculation “clove” to “loaf” in the generated transcript). |
Injecting eyesight utilizing lightweight modules
Our intention is to insert visual being familiar with abilities to an present audio-only ASR design although protecting its generalization functionality to different domains (both of those AV and audio-only domains).
To realize this, we augment an existing condition-of-the-artwork ASR design (Most effective-RQ) with the adhering to two elements: (i) linear visual projector and (ii) light-weight adapters. The previous jobs visual capabilities in the audio token embedding house. This approach will allow the model to effectively hook up individually pre-trained visual feature and audio enter token representations. The latter then minimally modifies the model to increase knowledge of multimodal inputs from films. We then teach these extra modules on unlabeled web films from the HowTo100M dataset, together with the outputs of an ASR product as pseudo ground reality, whilst maintaining the rest of the Best-RQ product frozen. These types of light-weight modules empower facts-efficiency and sturdy generalization of functionality.
We evaluated our extended model on AV-ASR benchmarks in a zero-shot setting, in which the model is in no way skilled on a manually annotated AV-ASR dataset.
Curriculum finding out for eyesight injection
Following the original evaluation, we discovered empirically that with a naïve single round of joint coaching, the design struggles to study both of those the adapters and the visual projectors in one particular go. To mitigate this situation, we released a two-phase curriculum finding out method that decouples these two elements — area adaptation and visible element integration — and trains the community in a sequential method. In the 1st stage, the adapter parameters are optimized without the need of feeding visual tokens at all. The moment the adapters are properly trained, we include the visual tokens and prepare the visual projection levels on your own in the 2nd stage whilst the qualified adapters are stored frozen.
The to start with stage focuses on audio area adaptation. By the next phase, the adapters are fully frozen and the visible projector need to merely discover to crank out visible prompts that challenge the visual tokens into the audio area. In this way, our curriculum studying strategy allows the design to incorporate visual inputs as nicely as adapt to new audio domains in AV-ASR benchmarks. We utilize each individual phase just once, as an iterative application of alternating phases qualified prospects to effectiveness degradation.
 |
| Total architecture and education technique for AVFormer. The architecture consists of a frozen Conformer encoder-decoder model, and a frozen CLIP encoder (frozen levels proven in grey with a lock image), in conjunction with two light-weight trainable modules – (i) visible projection layer (orange) and bottleneck adapters (blue) to allow multimodal area adaptation. We propose a two-phase curriculum finding out strategy: the adapters (blue) are very first trained with out any visual tokens, immediately after which the visual projection layer (orange) is tuned though all the other elements are stored frozen. |
The plots under display that without having curriculum discovering, our AV-ASR design is even worse than the audio-only baseline throughout all datasets, with the hole increasing as extra visible tokens are added. In contrast, when the proposed two-phase curriculum is used, our AV-ASR model performs appreciably superior than the baseline audio-only product.
 |
| Outcomes of curriculum studying. Purple and blue strains are for audiovisual types and are shown on 3 datasets in the zero-shot setting (reduce WER % is superior). Applying the curriculum will help on all 3 datasets (for How2 (a) and Moi4D (c) it is important for outperforming audio-only functionality). Effectiveness increases up right up until 4 visual tokens, at which issue it saturates. |
Effects in zero-shot AV-ASR
We assess AVFormer to Best-RQ, the audio edition of our model, and AVATAR, the point out of the artwork in AV-ASR, for zero-shot efficiency on the 3 AV-ASR benchmarks: How2, VisSpeech and Ego4D. AVFormer outperforms AVATAR and Ideal-RQ on all, even outperforming both equally AVATAR and Most effective-RQ when they are experienced on LibriSpeech and the entire established of HowTo100M. This is noteworthy because for Finest-RQ, this will involve instruction 600M parameters, whilst AVFormer only trains 4M parameters and therefore involves only a small fraction of the training dataset (5% of HowTo100M). Also, we also evaluate efficiency on LibriSpeech, which is audio-only, and AVFormer outperforms both baselines.
.png) |
| Comparison to state-of-the-artwork techniques for zero-shot overall performance throughout different AV-ASR datasets. We also show performances on LibriSpeech which is audio-only. Success are claimed as WER % (reduce is much better). AVATAR and Finest-RQ are finetuned conclusion-to-close (all parameters) on HowTo100M while AVFormer works proficiently even with 5% of the dataset thanks to the small established of finetuned parameters. |
Conclusion
We introduce AVFormer, a light-weight system for adapting existing, frozen point out-of-the-art ASR models for AV-ASR. Our method is useful and successful, and achieves extraordinary zero-shot efficiency. As ASR models get more substantial and larger sized, tuning the full parameter set of pre-experienced types will become impractical (even additional so for unique domains). Our system seamlessly enables both of those area transfer and visible input mixing in the similar, parameter effective design.
Acknowledgements
This research was carried out by Paul Hongsuck Search engine optimization, Arsha Nagrani and Cordelia Schmid.
[ad_2]
Source hyperlink