
[ad_1]
In-context mastering is a natural language paradigm that demonstrates the capacity of pre-properly trained types to pick up new behaviors utilizing only a little number of example prompts as enter. Most modern investigation indicates that large language models (LLMs), these types of as GPT-3 and the latest craze, ChatGPT, can achieve outstanding functionality when it arrives to in-context handful of-shot finding out on information-intensive NLP jobs. For instance, LLMs have correctly shown their means to respond to arbitrary factual queries relating to open up-domain query answering, which basically refers to producing responses to arbitrary context-free queries. Researchers have located that retrieval augmentation can be incredibly advantageous for understanding-intensive things to do, which can further enhance the performance of LLMs. LLMs conduct retrieval augmentation by extracting appropriate paperwork from an exterior corpus.
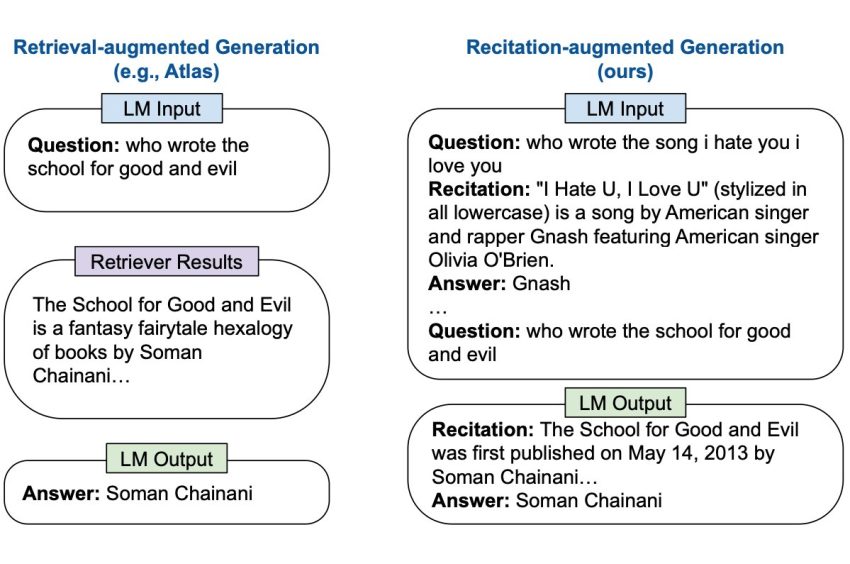
Nevertheless, about the previous number of yrs, researchers have questioned no matter whether LLMs are capable of making factual details that is extra correct without the need of the assist of retrieval augmented generation. A workforce of researchers at Google Brain and CMU performed some ground-breaking analysis do the job that illustrates exactly this! The group has set forth a brand name-new solution referred to as RECITation-augmented Technology (RECITE), in which, for a specified input, RECITE to start with utilizes sampling to remember a person or much more pertinent passages from the LLMs’ very own reminiscences ahead of building the ultimate benefits. RECITE’s ground breaking recite-and-remedy strategy has shown state-of-the-art effectiveness in a wide variety of expertise-intense NLP responsibilities, together with shut-guide query answering (CBQA). The team’s analysis paper was also revealed at the prestigious ICLR 2023 conference.
The paradigm introduced by Google Brain scientists is based on dividing unique information-intensive work into two subtasks: activity execution and information recitation. Recitation can be regarded as an intermediate awareness retrieval course of action, whilst process execution is the final period whereby the remaining outputs are created. The researchers discovered that though couple-shot prompting can aid LLMs in undertaking specific NLP responsibilities, these responsibilities are normally not in a very similar format to the unique causal language modeling pre-schooling objective. This regularly tends to make it difficult for LLMs to recall facts correctly from memory. As a end result, this observation gave the researchers the thought to use an supplemental awareness-recitation move. The awareness-recitation stage was provided to simulate the language modeling pre-coaching assignment, eventually improving upon LLMs’ ability to deliver factual facts.
The researchers’ top goal was to simulate a human’s ability to remember pertinent factoids ahead of responding to know-how-intense queries. The team tested and good-tuned their recite-and-solution scheme for couple of-shot shut-book query answering (CBQA) jobs. These jobs consist of two components: the proof recitation module, which calls for studying pertinent passages, and the concern-remedy module, which asks you to occur up with responses based mostly on the evidence you just recited. The scientists presented a prompt-based studying-to-recite program making use of the LLM’s capacity for in-context studying. Paired illustrations of thoughts and recited proof ended up presented as input to the LLMs to learn these types of situations in an in-context way to recite the issue.
The researchers ran many checks on four pre-trained products (PaLM, UL2, Choose, and Codex) and three CBQA tasks (Purely natural Queries, TriviaQA, and HotpotQA) to assess their RECITE paradigm. It was observed that making use of diverse pre-trained language products with the suggested recite-and-remedy strategy, CBQA efficiency on the All-natural Inquiries and TriviaQA datasets could be significantly enhanced. The scientists also made an appealing observation that even though overall performance boosts on NQ have been more uniform across various language products, enhancements from recite-and-respond to on TriviaQA had been far more significant on lesser language versions. The most likely trigger of this could possibly be that Trivia-design and style inquiries commonly consist of more contextual info, which lessens the impression of recitation for powerful LLMs like PaLM.
Even if the method created by Google Brain Scientists is extraordinary, far more perform requires to be carried out. In order to update time-sensitive info, a pure LLM-centered resolution now requires instruction or fine-tuning the LLMs on the new corpus, which can be quite computationally costly. The scientists want to function on this entrance in the in the vicinity of future. What’s more, in accordance to their long run strategies, the scientists also program on validating the effectiveness of recitation-augmented technology for added awareness-intensive NLP duties in the closed-reserve context, like actuality-checking.
Examine out the Paper and Github. All Credit For This Research Goes To the Researchers on This Job. Also, don’t fail to remember to join our 15k+ ML SubReddit, Discord Channel, and E-mail Publication, exactly where we share the hottest AI investigate news, awesome AI tasks, and far more.
Khushboo Gupta is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Technologies(IIT), Goa. She is passionate about the fields of Device Finding out, Organic Language Processing and Web Improvement. She enjoys learning far more about the technological field by participating in various problems.
[ad_2]
Supply link