
[ad_1]
Big language models (LLMs) have taken the tech industry by storm in the past few yrs. These language models, trained on vast amounts of facts, can execute a variety of responsibilities, ranging from elementary ones like summarising textual content and crafting poetry to a lot more complicated kinds like generating AI artwork prompts and even predicting protein construction. OpenAI’s ChatGPT is at the moment amid the best and most well-acknowledged illustrations of this sort of LLMs. Working with Generative Pre-educated Transformer 3, ChatGPT is a dialogue-primarily based AI chat interface that can converse with persons, compose code, solution inquiries, and even remedy difficult mathematical equations. Even other tech giants, like Google and Microsoft, have however to leave any stone unturned in releasing their language styles like BARD and Bing.
It is a extensively held belief among the teachers that incorporating a lot more parameters increases overall performance when training LLMs with practically a billion parameters. Current investigation demonstrates that for a specified teaching compute spending budget, more compact types experienced on extra details, as opposed to the major types, create the most effective functionality. Inference funds is an additional critical parameter vital for getting a sought after diploma of functionality. Whilst it may be cheaper to train a big product to achieve a certain degree of functionality, a more compact one experienced for a longer time will ultimately be more affordable at inference. In some circumstances, the great design is not the a single that trains the fastest but the one that will make inferences the swiftest.
To make its mark in the competitive generative AI model race, Facebook’s dad or mum corporation, Meta, introduces its line of AI language types less than the title LLaMA. This work aims to produce many language products that perform optimally at different inference budgets, inspiring the AI community to conduct investigation on building much more dependable language types. Previously, entry to this kind of language types was pricey and limited since they routinely demanded servers to run. But with LLaMA, Meta aims to remedy specifically that for scientists. Trained on only publicly readily available knowledge, the firm promises that LLaMA can outperform more substantial AI versions currently in use, which includes OpenAI’s older GPT-3 model. The organization has carried out outstanding operate in exhibiting the simple fact that it is possible to educate state-of-the-artwork types without having resorting to proprietary and inaccessible datasets.
Meta has open-sourced LLaMA with the hope that the models will support democratize the entry and examine of LLMs considering the fact that they can be operate on a single GPU. This will enable researchers to understand LLMs additional thoroughly and minimize other acknowledged complications, together with bias, toxicity, and the capability to distribute misinformation. Yet another intriguing factor of this collection of language designs is that, in distinction to other language styles like ChatGPT and Bing, LLaMA is solely meant for study functions and is dispersed underneath a “noncommercial license.” Access is at this time obtainable to a wide variety of educational scientists, governments, universities, and other academic institutions.
LLaMA can create human-like dialogues from a textual content enter prompt like other AI-powered chatbots. 4 distinct versions are readily available, with parameters ranging from 7 billion to 65 billion. In contrast to OpenAI’s earlier GPT-3 product, it is almost ten instances more compact. Only publicly available details from many domains that had currently been utilized to practice other LLMs have been employed to prepare the sequence of foundation types. This produced it a lot easier for the versions to be open-sourced. English CCNet, C4, GitHub, Wikipedia, Guides, ArXiv, and Stack Exchange are some information sources utilised to coach LLaMA. The transformer design and style serves as the foundation for LLaMA, with additional developments staying introduced about the training course of the past handful of decades. Researchers at Meta experienced huge transformers on a vast amount of money of textual information utilizing a common optimizer.
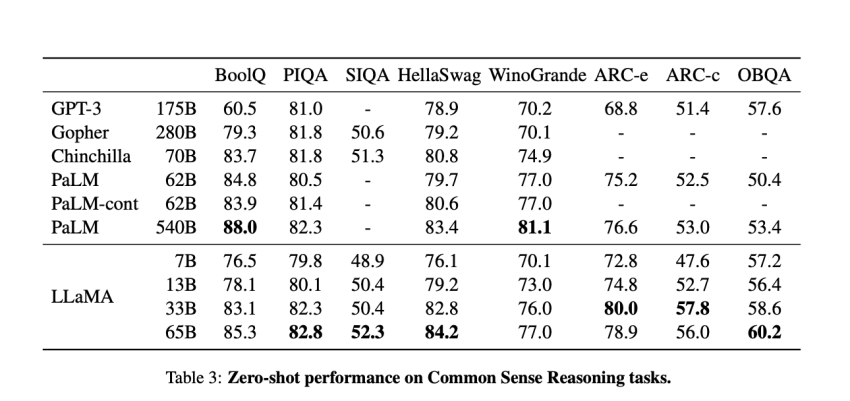
One particular trillion tokens ended up employed in the instruction of the smallest model, LLaMA-7B. On the other hand, models with bigger parameters like LLaMA-33B and LLaMA-65B have been qualified on 1.4 trillion tokens. The scientists assessed their sequence of foundation types utilizing a wide variety of benchmarks, which include BoolQ, WinoGrande, OpenBookQA, NaturalQuestions, RealToxicityPrompts, WinoGender, and some others. The researchers’ two most critical findings are that the LLaMA-13B design, the second-smallest version, outperforms the more mature GPT-3 model on most benchmarks, and the LLaMA-65B model is aggressive with some of the ideal designs now available, including DeepMind’s Chinchilla-70B and Google’s PaLM-540B styles.
In a nutshell, Meta produced a collection of novel state-of-the-artwork AI LLMs known as LLaMA for researchers hoping to progress study on LLMs and strengthen their robustness. The researchers have discovered that good-tuning these designs on recommendations prospects to positive outcomes when it arrives to future perform. The researchers will carry out further investigation on this. In order to make improvements to functionality, Meta also seeks to deploy more substantial designs that have been skilled on far more sizeable corpora.
Test out the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Task. Also, don’t ignore to join our 14k+ ML SubReddit, Discord Channel, and Email Publication, wherever we share the most current AI investigate news, great AI jobs, and additional.
Khushboo Gupta is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Device Understanding, All-natural Language Processing and Website Development. She enjoys understanding more about the technical field by participating in many worries.
[ad_2]
Supply url