
[ad_1]
Synthetic intelligence is revolutionary in all the significant use conditions and purposes we face every day. One particular this sort of place revolves all around a great deal of audio and visual media. Imagine about all the AI-driven applications that can create amusing movies, and artistically astounding visuals, duplicate a celebrity’s voice, or note down the whole lecture for you with just one particular click on. All of these designs need a substantial corpus of info to prepare. And most of the successful techniques depend on annotated datasets to teach on their own.
The most important obstacle is to retail outlet and annotate this knowledge and rework it into usable facts factors which products can ingest. Easier explained than done corporations want enable gathering and creating gold-common information factors each and every calendar year.
Now, scientists from MIT, the MIT-IBM Watson AI Lab, IBM Analysis, and other institutions have developed a groundbreaking method that can efficiently resolve these issues by examining unlabeled audio and visible facts. This design has a good deal of assure and probable to boost how existing types coach. This technique resonates with numerous products, this kind of as speech recognition versions, transcribing and audio creation engines, and item detection. It brings together two self-supervised learning architectures, contrastive mastering, and masked data modeling. This tactic follows a person basic notion: replicate how individuals understand and realize the planet and then replicate the very same actions.
As explained by Yuan Gong, an MIT Postdoc, self-supervised discovering is vital due to the fact if you appear at how humans obtain and understand from the knowledge, a huge portion is without the need of direct supervision. The objective is to permit the exact course of action in equipment, making it possible for them to master as many features as achievable from unlabelled info. This instruction gets to be a potent foundation that can be used and enhanced with the assistance of supervised finding out or reinforcement understanding, dependent on the use situations.
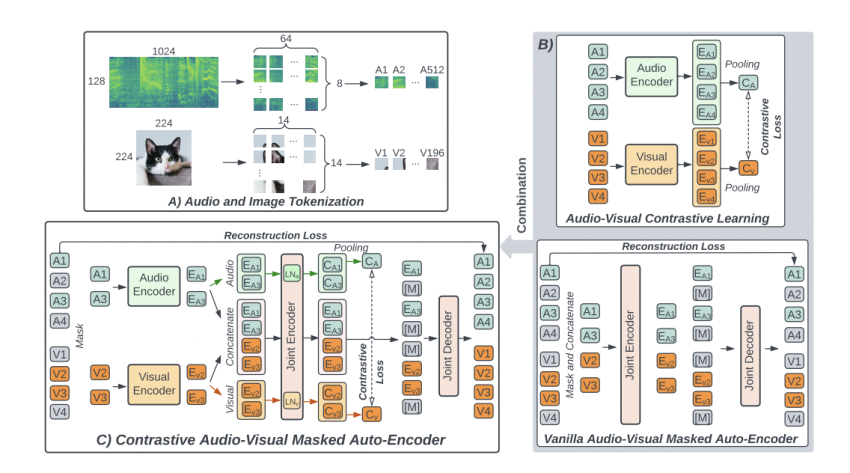
The procedure utilised here is contrastive audio-visible masked autoencoder (CAV-MAE), which takes advantage of a neural community to extract and map meaningful latent representations from audio and visible info. The types can be experienced on significant datasets of 10-next YouTube clips, utilizing audio and video clip components. The scientists claimed that CAV-MAE is much far better than any other prior techniques since it explicitly emphasizes the association concerning audio and visual data, which other solutions never include.
The CAV-MAE strategy incorporates two methods: masked information modeling and contrastive learning. Masked data modeling consists of:
- Taking a movie and its matched audio waveform.
- Converting the audio to a spectrogram.
- Masking 75% of the audio and video clip details.
The product then recovers the lacking details by a joint encoder/decoder. The reconstruction reduction, which actions the change concerning the reconstructed prediction and the authentic audio-visual blend, is utilised to practice the product. The key aim of this method is to map similar representations near to just one another. It does so by associating the appropriate pieces of audio and movie information, these kinds of as connecting the mouth movements of spoken phrases.
The tests of CAV-MAE-based types with other models proved to be incredibly insightful. The assessments have been done on audio-video clip retrieval and audio-visual classification jobs. The benefits shown that contrastive studying and masked data modeling are complementary methods. CAV-MAE outperformed previous procedures in party classification and remained aggressive with versions skilled making use of market-stage computational sources. In addition, multi-modal information noticeably enhanced high-quality-tuning of one-modality illustration and functionality on audio-only function classification jobs.
The scientists at MIT think that CAV-MAE represents a breakthrough in progress in self-supervised audio-visual finding out. They envision that its use cases can selection from action recognition, like athletics, instruction, enjoyment, motor vehicles, and general public protection, to cross-linguistic automated speech recognition and audio-video clip generations. Whilst the present-day approach focuses on audio-visual info, the scientists goal to prolong it to other modalities, recognizing that human perception consists of several senses outside of audio and visual cues.
It will be interesting to see how this solution performs around time and how numerous existing versions check out to integrate these types of strategies.
The scientists hope that as device studying innovations, procedures like CAV-MAE will turn out to be significantly worthwhile, enabling types to fully grasp superior and interpret the earth.
Check out Out The Paper and MIT Web site. Don’t neglect to join our 23k+ ML SubReddit, Discord Channel, and E mail Newsletter, where by we share the hottest AI study information, great AI assignments, and far more. If you have any inquiries with regards to the over report or if we skipped just about anything, experience absolutely free to e mail us at [email protected]
🚀 Check Out 100’s AI Equipment in AI Tools Club

Anant is a Computer science engineer currently performing as a knowledge scientist with practical experience in Finance and AI goods as a service. He is eager to build AI-run solutions that build superior details factors and resolve each day daily life problems in an impactful and productive way.
[ad_2]
Supply link