

[ad_1]
I’d like to share a trick I’ve located handy in setting up a lab to validate configurations. Plus, just one other trick that may possibly even be practical in manufacturing.
The hope is you might uncover this helpful in creating a lab with fewer products. As normally, there is a tradeoff: a bit far more complexity in your configurations and tests.
Actual-environment Use Case
I just lately labored with an organization that planned to deploy an IOS-XR NCS 540 primarily based community working MPLS, supporting IP multicast, with QoS. 1 target was to generate and validate configuration templates. The next was to pin down some of the protocol details and behaviors, as nicely as a few of style and design specifics.
We crafted a lab with 3 x NCS routers as MPLS PE (supplier edge) routers, but just a single Cat 9300 as CE (consumer edge) unit. Then made use of VRFs to make the Cat 9300 act like a few unique web page L3 switches.
We used 3 NCS routers because we wished minimum lab artifacts in their configurations, prototype config templates. The Cat 9300 was just going to be undertaking VRF-Lite, well-recognized territory, so we could be more versatile with how it was configured.
And certainly, we could possibly have just thrown 3 x Cat9300 in, but the tactic utilized lowered the selection of boxes to scrounge, the room necessary, and a bit of power/cabling.
Here’s the actual physical diagram:
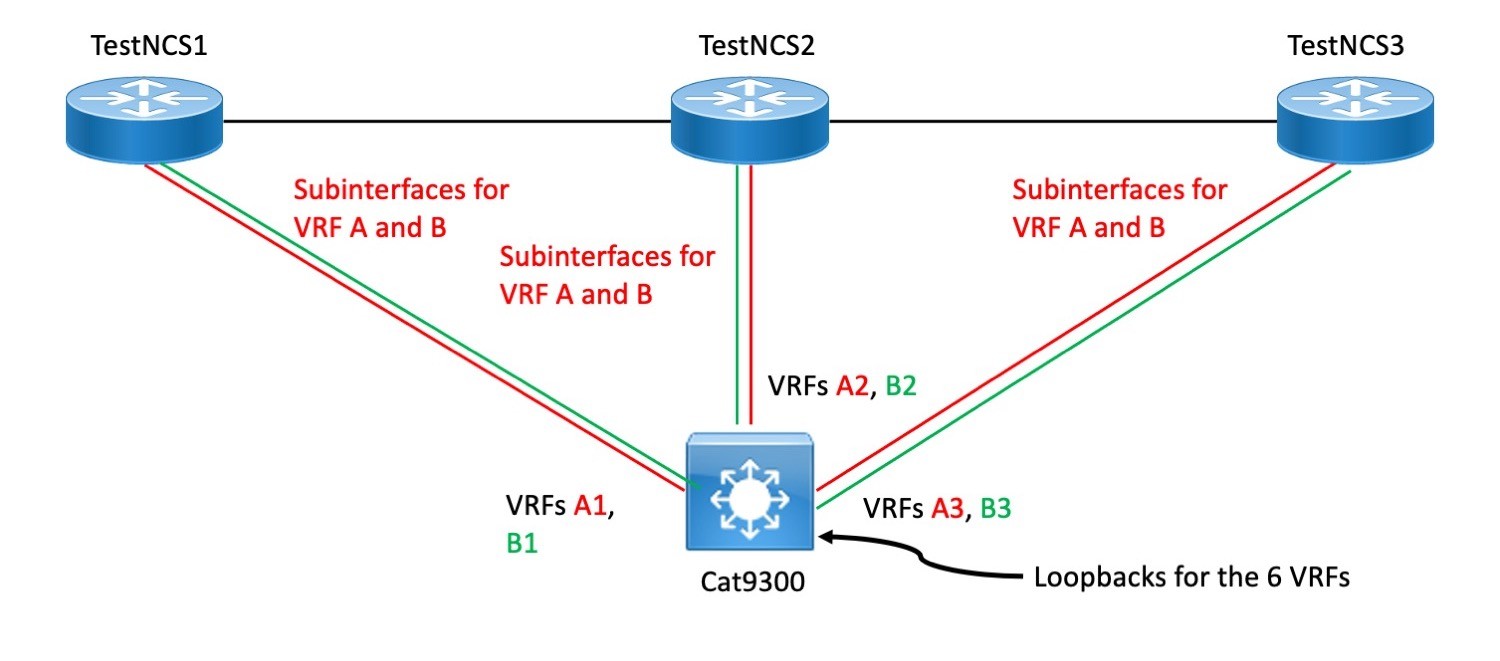
Logically, it is more like the next:
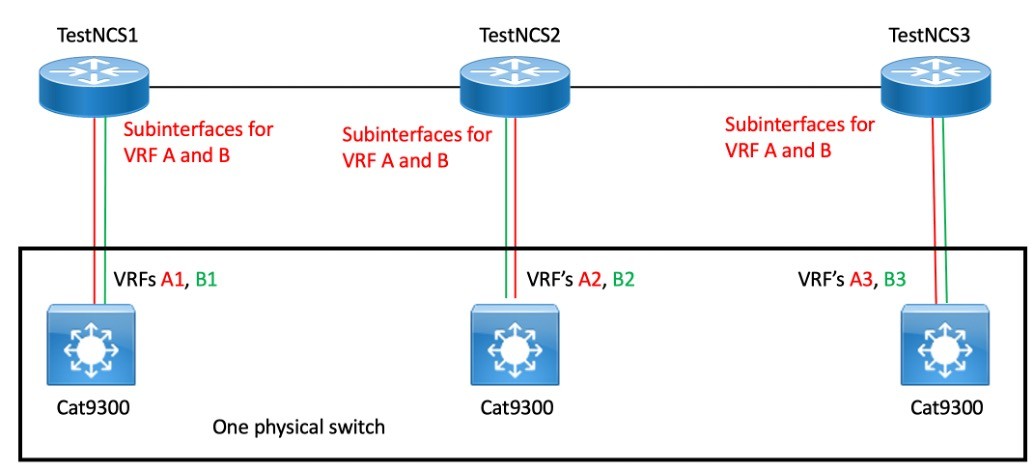
What makes this get the job done is that the VRF title is a area assemble. So overall VRFs A and B can be independently routed to the nearby routing VRFs A1/B1, A2/B2, and A3/B3 dependent on the connecting interfaces. We think of the latter as A and B, but they simulate A and B VRFs on distinctive chassis, for all applications.
The doing the job diagram had addresses, BGP ASNs, and so forth. in it – I taken out them as not pertinent to this blog.
The thought below was that in manufacturing, we’d have VRFs A and B, and very likely other folks. But two was enough for drafting config templates and screening.
On the Cat 9300, we’d usually have VRFs A and B as effectively. But to mimic 3 diverse Cat 9300s and their routing tables, we alternatively have the VRFs A1, A2, A3, and B1, B2, B3.
The primary price of doing this was owning to bear in mind to do items like the pursuing:
ping vrf A1 x.x.x.x (in which x.x.x.x was an deal with in VRF A3)
You can consider of that as pinging out VRF A on faux change 1, to hit an handle in VRF A on faux switch 3. (Assuming undertaking it that way is valuable.)
Having Multicast Into the Act
I have identified that when under time force or late at night time (or not so late at night, now that I have gotten older), very simple troubleshooting is great. Matters like checking the routing desk are great. Issues like wanting at MPLS label bindings and forwarding could be vital, but they can need additional thought and can choose time. Not easy, in other phrases.
Multicast has occur up progressively frequently, primarily in a couple of contexts:
- Intercom-like voice software as element of area maintenance crew comms
- Videos in health care environment, e.g., distant critique of ultrasound or other video clip-like visuals
When multicast is a essential element of the structure, how do you do very simple? Primarily considering that numerous persons feel that multicast routing / PIM is anything at all but easy. (And I have discovered a couple of its surprising behaviors the tricky way about the years – prior outdated weblogs.)
The lab trick that I have commencing working with in production is to build a loopback interface and put an IGMP be a part of-group command on it, for a one of a kind per-product multicast team.
What that buys you is the capability to multicast ping the loopback. Which was very helpful in the lab depicted earlier mentioned.
In certain, I could use commands like the subsequent to verify features or assistance troubleshoot:
ping vrf A1 224.1.2.3 rep 10000 time
That sends 10000 pings to the multicast team demonstrated, which was the IGMP be part of IPmc group on a loopback in VRF A3. I.e. phony swap 1 sending pings to a multicast vacation spot throughout the MPLS to faux swap 3s loopback. If items are functioning, you should get at least some replies again (modulo COPP rate-restricting or CPU impact and so on.)
That was very helpful in finding the MPLS multicast doing the job.
Oh, and many thanks Cisco for the obstacle made by the documentation omitting a pair of the NCS 540 multicast information and any dialogue of configuration choices in that regard. Offset by Ryan’s (you know who you are) support!
In which the multicast is essential, just one could possibly even constantly deliver probes to verify ping response. We’re contemplating carrying out that for a person clinic, as early warning of an IPmc issue.
I have no notion no matter whether ThousandEyes, CatchPoint, Netbeez, and other equipment can do multicast ping, despite the fact that I’d hope they would. The check code in such tools ought not to will need modification.
By the way, the multicast ping reply is unicast, which matters if you’re attempting to do WireShark or capture packets. Or have ACLs.
Conclusion
The earlier mentioned summarizes a few of tricks I have located useful in labbing and testing more than the several years, especially when spare machines is scarce.
By the way, I do strongly propose that with the onset of GUI automation equipment like DNAC and ACI, owning a lab to check “what takes place if I do this” can be darn useful! With automation you have a bigger “blast radius” (opportunity human-induced outage scope?) so it is wise to be very careful, and take a look at just before producing improvements.
(Particularly the “no-brainer” kinds – if you do not apply significantly believed contemplating the transform is simple, they are the types that can appear back again and bite you! Also, automation may perhaps sometimes do a thing a bit distinct than you assume, significantly when it will come to backing out configuration lines to update a configuration.)


[ad_2]
Source connection