
[ad_1]
Above the final couple several years, autoregressive Transformers have brought a continuous stream of breakthroughs in generative modeling. These models generate every ingredient of a sample – the pixels of an picture, the figures of a textual content (usually in “token” chunks), the samples of an audio waveform, and so on – by predicting one particular element after the other. When predicting the subsequent element, the model can glance back at individuals that had been developed earlier.
Nonetheless, every single of a Transformer’s levels grows additional costly as far more elements are employed as enter, and practitioners can only afford to pay for to prepare deep Transformers on sequences no extra than about 2,048 things in length. And so, most Transformer-dependent designs overlook all things beyond the most modern previous (close to 1,500 words or 1/6 of a compact graphic) when creating a prediction.
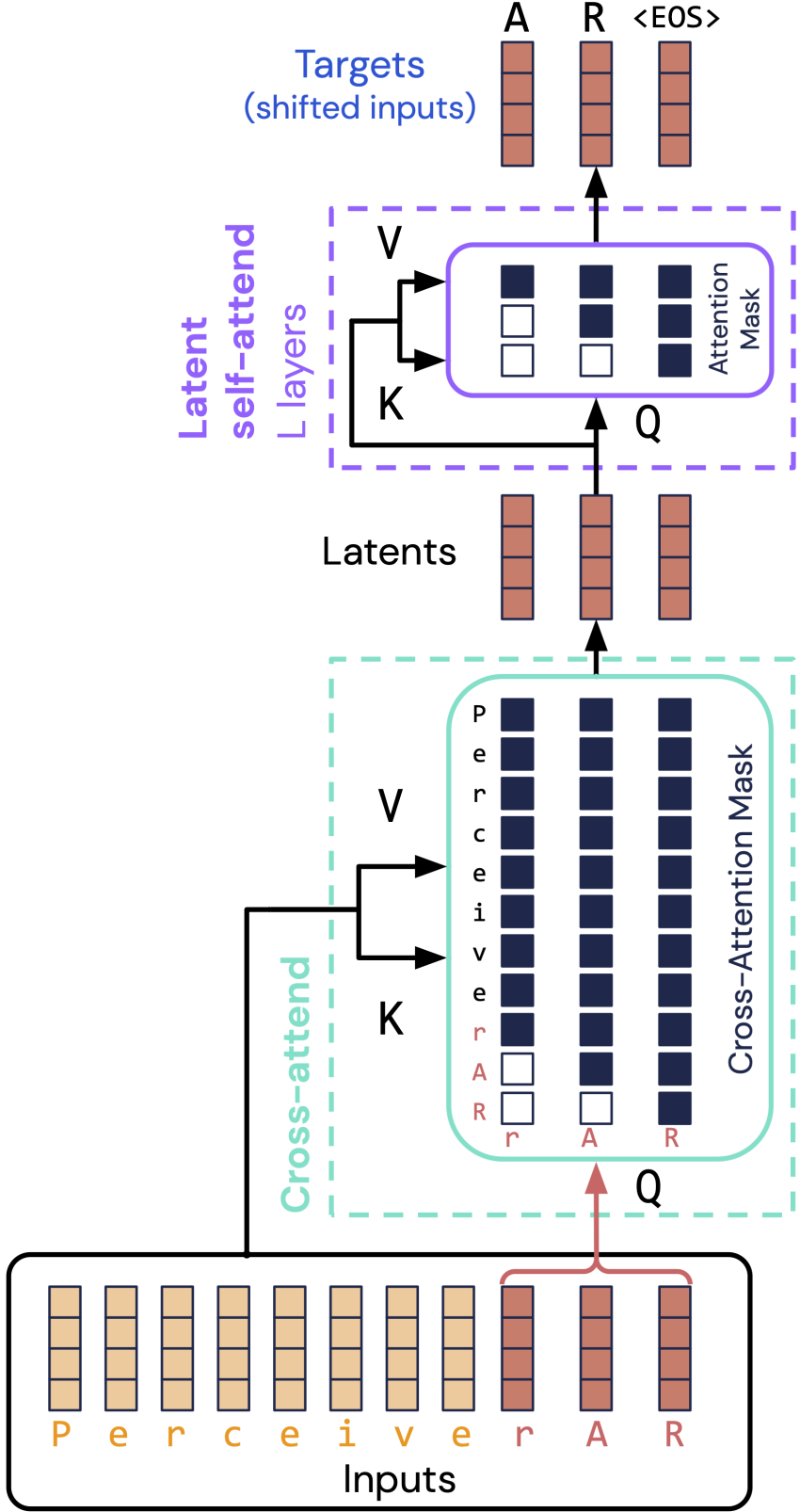
In contrast, our just lately developed Perceiver models give excellent results on a range of actual-earth jobs with up to all-around 100,000 components. Perceivers use cross-awareness to encode inputs into a latent place, decoupling the input’s compute specifications from product depth. Perceivers also devote a mounted price, regardless of input sizing, at just about every single layer.
Though latent-place encoding handles all features in a solitary go, autoregressive generation assumes processing happens 1 aspect at a time. To deal with this issue, Perceiver AR proposes a basic answer: align the latents 1 by a single with the remaining aspects of the enter, and thoroughly mask the input so latents see only earlier components.

The end result is an architecture (demonstrated above) that attends to as a great deal as 50x for a longer time inputs as regular Transformers, although deploying as widely (and fundamentally as quickly) as regular decoder-only Transformers.

Perceiver AR scales noticeably much better with dimensions than both regular Transformers and Transformer-XL types at a array of sequence lengths in true phrases. This home will allow us to establish pretty efficient prolonged-context types. For instance, we find that a 60-layer Perceiver AR with context duration 8192 outperforms a 42-layer Transformer-XL on a e-book-duration technology task, while jogging a lot quicker in serious wall-clock conditions.
On common, very long-context picture (ImageNet 64×64), language (PG-19), and new music (MAESTRO) technology benchmarks, Perceiver AR makes state-of-the-art benefits. Increasing enter context by decoupling enter size from compute spending budget sales opportunities to a number of intriguing final results:
- Compute spending plan can be tailored at eval time, enabling us to expend less and smoothly degrade high-quality or to devote more for enhanced generation.
- A greater context allows Perceiver AR to outperform Transformer-XL, even when expending the same on compute. We obtain that larger context potential customers to improved design overall performance even at inexpensive scale (~1B parameters).
- Perceiver AR’s sample good quality exhibits a lot significantly less sensitivity to the order in which it generates factors. This helps make Perceiver AR straightforward to implement to configurations that do not have a pure remaining-to-right purchasing, this sort of as knowledge like photographs, with framework that spans far more than just one dimension.
Making use of a dataset of piano audio, we qualified Perceiver AR to create new parts of music from scratch. Due to the fact every single new notice is predicted based mostly on the whole sequence of notes that came in advance of, Perceiver AR is in a position to make items with a high amount of melodic, harmonic, and rhythmic coherence:
Master a lot more about applying Perceiver AR:
- Down load the JAX code for teaching Perceiver AR on Github
- Examine our paper on arXiv
- Verify out our highlight presentation at ICML 2022
See the Google Magenta site publish with much more new music!
[ad_2]
Resource url