
[ad_1]
Weakly supervised and unsupervised training approaches have demonstrated fantastic overall performance on numerous audio processing responsibilities, which include voice recognition, speaker recognition, speech separation, and search phrase recognizing, thanks to the availability of large-scale on the internet datasets. Scientists at Oxford created a speech recognition program known as Whisper that helps make use of this in depth database on a larger scale. Employing 125,000 hours of English translation details and 680,000 hrs of noisy speech education data in 96 additional languages, they show how weakly supervised pretraining of a easy encoder-decoder transformer can correctly attain zero-shot multilingual speech transcription on set up benchmarks.
Most educational benchmarks are designed up of short utterances, but in genuine-globe apps, this kind of as meetings, podcasts, and movies, transcription of prolonged-kind audio that might very last for several hours or minutes is generally needed. Due to memory constraints, the transformer patterns applied for automated speech recognition (ASR) models stop transcription of arbitrarily lengthy input audio (up to 30 seconds in the circumstance of Whisper). Latest investigation takes advantage of heuristic sliding-window style techniques, which are susceptible to errors due to the fact of I overlapping audio, which can trigger inconsistent transcriptions when the product processes the very same speech twice and (ii) incomplete audio, in which some terms may be skipped or incorrectly transcribed if they are at the beginning or conclude of the input section.
Whisper implies a buffered transcription strategy that is dependent on precise timestamp prediction to create how much the enter window must be shifted. As timestamp problems in one window might add to errors in successive home windows, this kind of a remedy is vulnerable to substantial drifting. They check out to reduce these errors applying a wide variety of hand-designed heuristics, but their endeavours typically fail to be successful. Whisper’s linked decoding, which utilizes a single encoder-decoder to decode transcriptions and timestamps, is susceptible to the conventional issues with car-regressive language generation, precisely hallucination, and repetition. This disastrously influences buffered transcription of very long-sort and other timestamp-delicate actions like speaker diarization, lip-reading, and audiovisual studying.
In accordance to the Whisper paper, a important chunk of the training corpus contains incomplete info (audio-transcription pairings devoid of timestamp data), represented by the token |nottimestamps|>. When scaling on incomplete and noisy transcription data, speech transcription general performance is inadvertently traded for fewer specific timestamp prediction. As a result, utilizing further modules, the transcript, and speech must be exactly aligned. There is a tonne of effort and hard work on “forced alignment,” which aligns speech transcription with audio waveforms at the phrase- or phoneme-degree. The acoustic mobile phone types are often skilled to benefit from the Concealed Markov Design (HMM) framework and the by-product or service of likely point out alignments.
The timestamps for these words and phrases or cell phone numbers are usually corrected utilizing external boundary correction products. A few current scientific tests use deep finding out methods for compelled alignment, such as utilizing a bi-directional attention matrix or CTC segmentation with the stop-to-finish experienced model thanks to the fast progress of deep mastering-primarily based approaches. Combining a reducing-edge ASR product with a uncomplicated phoneme recognition model, each of which ended up well prepared making use of sizeable massive-scale datasets, may well final result in even further improvement.
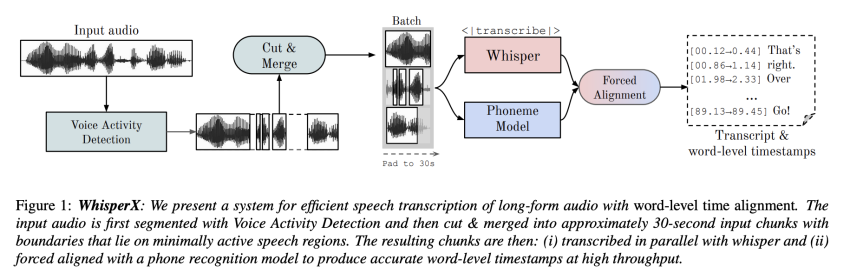
To conquer these issues, they counsel WhisperX, a technique for efficient voice transcription of extensive-variety audio with exact term-degree timestamps. It contains 3 additional measures in addition to whispering transcription:
- Pre-segmenting the enter audio with an external Voice Action Detection (VAD) design.
- Cutting and merging the resulting VAD segments into around 30-second enter chunks with boundaries on minimally lively speech areas.
- They force alignment with an exterior phoneme product to present specific term-amount timestamps.
Check out the Paper and Github. All Credit history For This Analysis Goes To the Researchers on This Challenge. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Publication, the place we share the most recent AI investigate information, interesting AI tasks, and far more.
Aneesh Tickoo is a consulting intern at MarktechPost. He is at present pursuing his undergraduate degree in Details Science and Synthetic Intelligence from the Indian Institute of Technological innovation(IIT), Bhilai. He spends most of his time doing the job on assignments aimed at harnessing the energy of device studying. His study curiosity is picture processing and is passionate about creating options close to it. He loves to connect with persons and collaborate on appealing tasks.
[ad_2]
Resource backlink