
[ad_1]
The fields of Artificial Intelligence and Equipment Discovering are solely dependent upon info. Everybody is deluged with facts from distinct resources like social media, healthcare, finance, and so forth., and this information is of wonderful use to apps involving Organic Language Processing. But even with so considerably facts, conveniently usable facts is scarce for coaching an NLP model for a certain process. Obtaining substantial-high quality details with usefulness and superior-top quality filters is a difficult endeavor. Specifically talking about building NLP designs for different languages, the absence of data for most languages arrives as a limitation that hinders progress in NLP for beneath-represented languages (ULs).
The rising duties like information summarization, sentiment evaluation, issue answering, or the growth of a virtual assistant all greatly depend on information availability in high-source languages. These responsibilities are dependent upon technologies like language identification, automatic speech recognition (ASR), or optical character recognition (OCR), which are primarily unavailable for less than-represented languages, to conquer which it is crucial to build datasets and evaluate styles on tasks that would be useful for UL speakers.
Just lately, a workforce of researchers from GoogleAI has proposed a benchmark termed XTREME-UP (Less than-Represented and Person-Centric with Paucal Facts) that evaluates multilingual types on consumer-centric responsibilities in a handful of-shot finding out setting. It largely focuses on functions that know-how users often conduct in their day-to-working day life, these types of as info entry and enter/output pursuits that permit other technologies. The 3 main characteristics that distinguish XTREME-UP are – its use of scarce data, its user-centric design and style, and its target on less than-represented languages.
With XTREME-UP, the scientists have introduced a standardized multilingual in-language fantastic-tuning location in area of the conventional cross-lingual zero-shot solution. This system considers the amount of knowledge that can be produced or annotated in an 8-hour period for a individual language, hence aiming to give the ULs a additional practical evaluation set up.
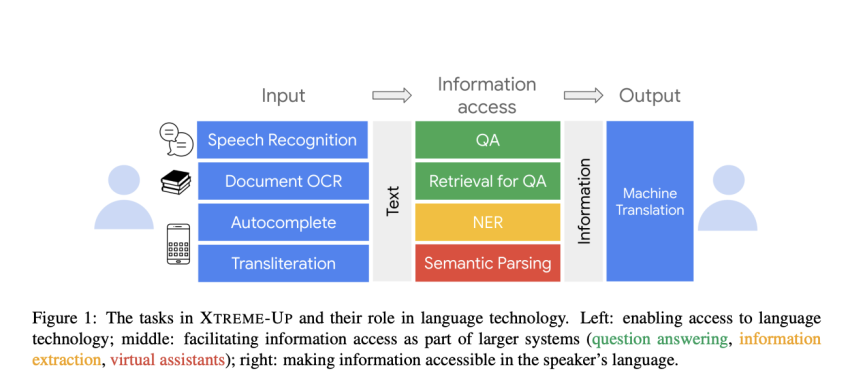
XTREME-UP assesses the functionality of language styles across 88 beneath-represented languages in 9 considerable person-centric systems, some of which consist of Automated Speech Recognition (ASR), Optical Character Recognition (OCR), Machine Translation (MT), and details access duties that have standard utility. The researchers have created new datasets especially for operations like OCR, autocomplete, semantic parsing, and transliteration in get to assess the abilities of the language products. They have also improved and polished the at the moment existing datasets for other tasks in the exact same benchmark.
XTREME-UP has a person of its crucial abilities to assess many modeling predicaments, like both equally textual content-only and multi-modal scenarios with visual, audio, and textual content inputs. It also provides strategies for supervised parameter adjustment and in-context understanding, permitting for a extensive evaluation of various modeling techniques. The responsibilities in XTREME-UP require enabling access to language technologies, enabling data access as portion of a bigger program these as concern answering, information and facts extraction, and digital assistants, followed by earning info accessible in the speaker’s language.
Consequently, XTREME-UP is a great benchmark that addresses the information scarcity challenge in remarkably multilingual NLP programs. It is a standardized analysis framework for underneath-represented language and appears to be seriously valuable for potential NLP exploration and developments.
Verify out the Paper and Github. Don’t overlook to join our 21k+ ML SubReddit, Discord Channel, and Email E-newsletter, the place we share the newest AI exploration information, awesome AI jobs, and additional. If you have any queries pertaining to the previously mentioned posting or if we missed just about anything, come to feel totally free to e-mail us at [email protected]
🚀 Look at Out 100’s AI Applications in AI Equipment Club
Tanya Malhotra is a remaining year undergrad from the University of Petroleum & Electricity Scientific tests, Dehradun, pursuing BTech in Personal computer Science Engineering with a specialization in Artificial Intelligence and Device Learning.
She is a Facts Science enthusiast with good analytical and vital thinking, together with an ardent interest in acquiring new abilities, main groups, and handling operate in an organized fashion.
[ad_2]
Resource url