
[ad_1]
Product specialization entails adapting a pre-experienced equipment-finding out design to a specific task or domain. In Language Types (LMs), model specialization is essential in increasing their performance in several tasks like summarization, concern-answering, translation, and language technology. The two main processes to specialize a language product to certain jobs are instruction wonderful-tuning (adapting a pre-skilled model to a new job or established of duties) and product distillation (transferring understanding from a pre-experienced, “teacher” design to a lesser, specialized, “student” design). Prompting is a essential strategy in the field of LM specialization, as it provides a way to guide the model toward certain behaviors, makes it possible for for more efficient use of confined training data, and is important for attaining point out-of-the-artwork efficiency. Compressing prompts is a technique staying examined with the hope of primary to sizeable personal savings in computing, memory, and storage and no significant reduce in the general performance or top quality of the output.
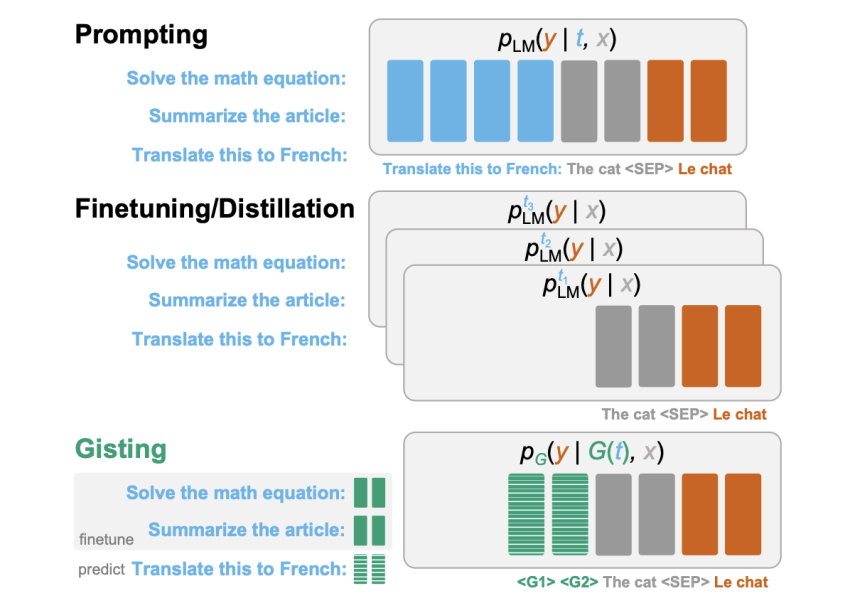
This paper, presented by researchers from Stanford College, proposes a novel approach for prompt compression identified as gisting, which trains an LM to compress prompts into scaled-down sets of “gist” tokens. In order to lessen the expense of the prompt, methods like great-tuning or distillation can be utilised to teach a model that would behave like the authentic one without having the prompt, but in that scenario, the model would have to be re-skilled for each individual new prompt, which is significantly from suitable. The notion at the rear of gisting, nevertheless, is to use a meta-discovering approach to predict gist tokens from a prompt which would not involve re-instruction the product for each individual job and would empower generalization to unseen guidelines with out additional teaching. This would occur with a reduction in computational price tag and would allow a prompt to be compressed, cached, and reused for compute performance. It would also make it possible for customers to match extra material into the restricted context window.
The authors experimented with a easy way of accomplishing this sort of a product – they employed the LM by itself (leveraging its pre-existing information) to forecast the gist tokens through the instruction good-tuning though modifying the Transformer interest masks. Given a (undertaking, enter) pair, they add gist tokens in between the activity and the input and set the consideration mask in the adhering to way: the enter tokens just after the gist tokens are not able to show up at to any of the prompt tokens in advance of the gist tokens (but they can attend to the gist tokens). Given the enter and the output are unable to attend to the prompt, this forces the design to compress the info from the prompt into the gist tokens in between.
To educate the gist models, they desired a dataset with a huge assortment of tasks, so they developed a dataset that they referred to as Alpaca+, which merged the details from two current instruction tuning datasets (Standford Alpaca and Self-Instruct) which totaled extra than 130k examples. They then held out 3 validation splits to be in a position to validate the product right after instruction which had Viewed, Unseen, and hand-crafted Human prompts. This way, they had been able to check the generalization to unseen directions, with the Human break up posing an even much better generalization challenge. They also used many LM architectures (specifically LLaMA-7Bm, a decoder-only GPT-type design, and FLAN-T5-XXL) and skilled gist models with a various amount of gist tokens (1, 2, 5, or 10). Nevertheless, the success showed that versions ended up usually insensitive to the variety of gist tokens, in some situations even exhibiting that a more substantial range of tokens was truly detrimental to efficiency. They, therefore, applied a one gist model for the rest of the experiments.
To evaluate the high quality of the prompt compression, they calibrated performance towards a positive handle, which was proficiently a standard instruction finetuning, which offered an higher sure on functionality, and a damaging control exactly where the model would not have entry to the instruction at all, resulting in random gist tokens, which furnished a reduce sure on effectiveness. To look at the outputs of their types to the beneficial management and measure a get amount versus it, they asked ChatGPT to pick out which response was superior, explaining its reasoning. They also applied a easy lexical overlap statistic termed ROUGE-L (a metric that actions similarities amongst generated textual content and human-prepared directions in open-ended instruction fine-tuning). A 50% acquire price suggests that the product is of comparable good quality to a design that does no prompt compression.
The success showed that on Seen directions, the gist products done incredibly intently to the favourable control versions with 48.6% (LLaMA) and 50.8% (FLAN-T5) earn costs. A lot more importantly, they had been ready to exhibit that the gist products experienced aggressive generalizations to unseen prompts, with 49.7% (LLaMA) and 46.2% (FLAN-T5) acquire rates. Only on the most complicated Human split they noticed slight drops in acquire rates (but nevertheless aggressive) with 45.8% (LLaMA) and 42.5% (FLAN-T5). The a little worse general performance of the FLAN-T5 and the specific failure conditions brought far more hypotheses to be examined in long run papers.
The researchers also investigated the opportunity efficiency gains that can be realized via gisting, which was the most important determination for the examine. The effects were remarkably encouraging, with gist caching leading to a 40% reduction in FLOPs and 4-7% reduced wall clock time in contrast to unoptimized types. Though these improvements were being identified to be scaled-down for decoder-only language designs, the scientists also demonstrated that gist types enabled a 26x compression of unseen prompts, giving significant added place in the enter context window.
In general, these conclusions illustrate the substantial likely of gisting for improving both of those the efficiency and effectiveness of specialized language styles. The authors also propose several promising directions for comply with-up perform on gisting. For example, they stipulate that the greatest compute and performance gains from gisting will occur from compressing more time prompts and that “gist pretraining” could make improvements to compression efficiency by first discovering to compress arbitrary spans of natural language prior to understanding prompt compression.
Check out out the Paper and Github. Don’t overlook to join our 19k+ ML SubReddit, Discord Channel, and E-mail Publication, in which we share the most recent AI research news, cool AI initiatives, and a lot more. If you have any thoughts relating to the earlier mentioned short article or if we skipped just about anything, feel absolutely free to email us at [email protected]
🚀 Look at Out 100’s AI Tools in AI Applications Club

Nathalie Crevoisier holds a Bachelor’s and Master’s degree in Physics from Imperial University London. She used a year finding out Applied Info Science, Device Learning, and World wide web Analytics at the Ecole Polytechnique Federale de Lausanne (EPFL) as aspect of her diploma. For the duration of her experiments, she made a eager fascination in AI, which led her to sign up for Meta (formerly Fb) as a Knowledge Scientist after graduating. During her four-calendar year tenure at the company, Nathalie worked on several groups, which includes Advertisements, Integrity, and Place of work, applying cutting-edge details science and ML instruments to resolve intricate problems impacting billions of buyers. Looking for much more independence and time to remain up-to-date with the hottest AI discoveries, she a short while ago made a decision to transition to a freelance vocation.
[ad_2]
Resource link