

[ad_1]
Segmentation, the method of identifying impression pixels that belong to objects, is at the core of personal computer vision. This system is used in purposes from scientific imaging to image modifying, and complex professionals need to have both of those extremely qualified talents and accessibility to AI infrastructure with substantial portions of annotated information for precise modeling.
Meta AI not long ago unveiled its Section Anything at all venture? which is ?an image segmentation dataset and model with the Segment Something Model (SAM) and the SA-1B mask dataset?—?the greatest at any time segmentation dataset help additional exploration in foundation types for computer vision. They created SA-1B accessible for analysis use when the SAM is certified below Apache 2. open license for any individual to test SAM with your pictures working with this demo!

Section Just about anything Model / Image by Meta AI
Ahead of, segmentation challenges have been approached using two lessons of methods:
- Interactive segmentation in which the consumers manual the segmentation process by iteratively refining a mask.
- Automated segmentation allowed selective object classes like cats or chairs to be segmented routinely but it needed massive quantities of annotated objects for schooling (i.e. countless numbers or even tens of hundreds of illustrations of segmented cats) together with computing resources and specialized know-how to practice a segmentation product neither tactic furnished a standard, totally automatic answer to segmentation.
SAM uses the two interactive and automatic segmentation in one particular model. The proposed interface allows adaptable usage, creating a extensive range of segmentation duties probable by engineering the correct prompt (these as clicks, containers, or textual content).
SAM was created applying an expansive, significant-high-quality dataset made up of more than one billion masks collected as portion of this challenge, supplying it the capability of generalizing to new kinds of objects and images outside of individuals noticed all through instruction. As a result, practitioners no more time require to acquire their segmentation facts and tailor a product exclusively to their use situation.
These abilities help SAM to generalize each throughout jobs and domains anything no other image segmentation application has completed before.
SAM will come with highly effective capabilities that make the segmentation endeavor extra effective:
- Range of input prompts: Prompts that direct segmentation allow for end users to conveniently perform distinctive segmentation duties without extra teaching prerequisites. You can use segmentation applying interactive points and bins, automatically section all the things in an picture, and deliver several valid masks for ambiguous prompts. In the determine down below we can see the segmentation is accomplished for particular objects making use of an input textual content prompt.

Bounding box employing textual content prompt.
- Integration with other devices: SAM can acknowledge input prompts from other units, these kinds of as in the long run taking the user’s gaze from an AR/VR headset and choosing objects.
- Extensible outputs: The output masks can serve as inputs to other AI units. For occasion, object masks can be tracked in video clips, enabled imaging enhancing apps, lifted into 3D area, or even made use of creatively this kind of as collating
- Zero-shot generalization: SAM has produced an understanding of objects which makes it possible for him to promptly adapt to unfamiliar kinds devoid of added teaching.
- Various mask technology: SAM can deliver numerous valid masks when confronted with uncertainty about an item remaining segmented, giving essential help when fixing segmentation in genuine-environment options.
- Authentic-time mask generation: SAM can produce a segmentation mask for any prompt in genuine time soon after precomputing the picture embedding, enabling actual-time interaction with the product.
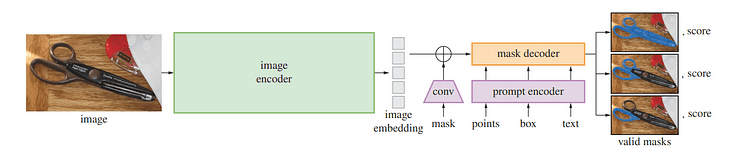
Overview of SAM product / Picture by Section Nearly anything
One particular of the the latest improvements in natural language processing and computer system eyesight has been foundation designs that permit zero-shot and number of-shot discovering for new datasets and tasks via “prompting”. Meta AI scientists educated SAM to return a legitimate segmentation mask for any prompt, these types of as foreground/background points, rough containers/masks or masks, freeform text, or any info indicating the target item inside an image.
A valid mask just indicates that even when the prompt could refer to multiple objects (for instance: just one stage on a shirt may well symbolize each by itself or an individual putting on it), its output need to present a affordable mask for one particular object only?—?therefore pre-teaching the model and solving basic downstream segmentation jobs by means of prompting.
The researchers observed that pretraining responsibilities and interactive details assortment imposed specific constraints on product style. Most noticeably, authentic-time simulation have to operate proficiently on a CPU in a web browser to let annotators to use SAM interactively in actual-time for efficient annotation. Even though runtime constraints resulted in tradeoffs between high quality and runtime constraints, basic styles developed satisfactory success in apply.
Underneath SAM’s hood, an picture encoder generates a a person-time embedding for pictures although a light-weight encoder converts any prompt into an embedding vector in real-time. These facts sources are then mixed by a lightweight decoder that predicts segmentation masks dependent on graphic embeddings computed with SAM, so SAM can generate segments in just 50 milliseconds for any supplied prompt in a world-wide-web browser.
Setting up and training the product calls for obtain to an enormous and assorted pool of information that did not exist at the get started of instruction. Today’s segmentation dataset launch is by considerably the premier to day. Annotators utilised SAM interactively annotate illustrations or photos ahead of updating SAM with this new info?—?repeating this cycle a lot of situations to continuously refine the two the design and dataset.
SAM would make collecting segmentation masks quicker than ever, taking only 14 seconds for each mask annotated interactively that system is only two moments slower than annotating bounding boxes which consider only 7 seconds making use of quick annotation interfaces. Equivalent big-scale segmentation info selection efforts include COCO entirely handbook polygon-centered mask annotation which requires about 10 several hours SAM model-assisted annotation efforts were even faster its annotation time for each mask annotated was 6.5x more quickly vs . 2x slower in conditions of information annotation time than prior product assisted significant scale info annotations endeavours!
Interactively annotating masks is insufficient to create the SA-1B dataset hence a facts motor was formulated. This knowledge motor has a few “gears”, starting off with assisted annotators ahead of relocating on to completely automatic annotation merged with assisted annotation to maximize the variety of gathered masks and last but not least totally automatic mask generation for the dataset to scale.
SA-1B’s remaining dataset attributes much more than 1.1 billion segmentation masks gathered on more than 11 million accredited and privacy-preserving photographs, producing up 4 periods as several masks than any existing segmentation dataset, according to human evaluation scientific studies. As verified by these human assessments, these masks exhibit large high-quality and variety when compared with previous manually annotated datasets with much lesser sample measurements.
Images for SA-1B have been attained by way of an graphic provider from several nations around the world that represented diverse geographic locations and profits concentrations. Even though selected geographic regions keep on being underrepresented, SA-1B delivers larger representation due to its larger sized selection of images and overall superior protection across all locations.
Scientists conducted checks aimed at uncovering any biases in the product across gender presentation, skin tone perception, the age variety of men and women as perfectly as the perceived age of individuals introduced, finding that the SAM model done similarly across numerous teams. They hope this will make the resulting operate much more equitable when used in authentic-earth use instances.
When SA-1B enabled the investigate output, it can also permit other researchers to prepare basis models for image segmentation. Moreover, this details may turn into the foundation for new datasets with further annotations.
Meta AI researchers hope that by sharing their research and dataset, they can speed up the analysis in graphic segmentation and image and video understanding. Due to the fact this segmentation design can perform this operate as aspect of larger systems.
In this posting, we covered what is SAM and its capacity and use conditions. Immediately after that, we went by means of how it works, and how it was qualified so as to give an overview of the design. Finally, we conclude the posting with the foreseeable future eyesight and work. If you would like to know far more about SAM make guaranteed to read through the paper and try out the demo.
Youssef Rafaat is a personal computer eyesight researcher & info scientist. His investigate focuses on developing serious-time laptop eyesight algorithms for health care applications. He also labored as a knowledge scientist for extra than 3 decades in the promoting, finance, and healthcare domain.
[ad_2]
Source hyperlink