

[ad_1]
Introducing RGB-Stacking as a new benchmark for vision-primarily based robotic manipulation
Choosing up a stick and balancing it atop a log or stacking a pebble on a stone may well seem to be like simple — and quite equivalent — steps for a particular person. Even so, most robots battle with handling a lot more than one particular such task at a time. Manipulating a adhere requires a different set of behaviours than stacking stones, hardly ever head piling different dishes on leading of a person a different or assembling home furniture. Just before we can teach robots how to accomplish these kinds of tasks, they 1st need to have to discover how to interact with a significantly greater selection of objects. As section of DeepMind’s mission and as a move toward producing a lot more generalisable and handy robots, we’re discovering how to enable robots to superior have an understanding of the interactions of objects with varied geometries.
In a paper to be introduced at CoRL 2021 (Conference on Robotic Mastering) and offered now as a preprint on OpenReview, we introduce RGB-Stacking as a new benchmark for vision-based mostly robotic manipulation. In this benchmark, a robot has to study how to grasp various objects and balance them on top rated of a single a different. What sets our exploration aside from prior function is the variety of objects used and the substantial amount of empirical evaluations done to validate our results. Our final results reveal that a blend of simulation and true-world knowledge can be utilised to master complicated multi-object manipulation and counsel a strong baseline for the open difficulty of generalising to novel objects. To help other researchers, we’re open up-sourcing a version of our simulated surroundings, and releasing the designs for setting up our genuine-robot RGB-stacking setting, alongside with the RGB-item models and data for 3D printing them. We are also open up-sourcing a selection of libraries and applications utilized in our robotics analysis far more broadly.
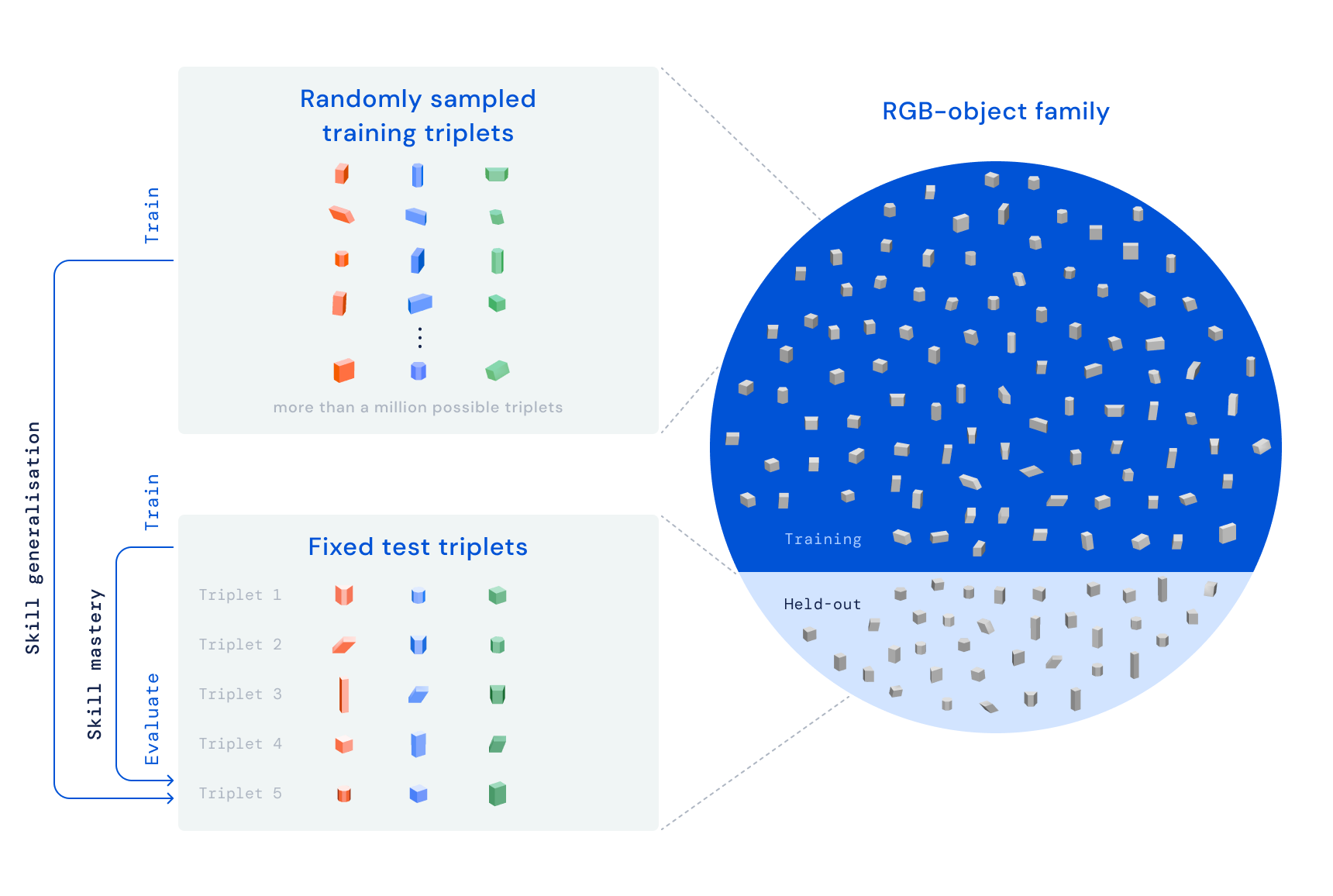
With RGB-Stacking, our objective is to train a robotic arm by way of reinforcement learning to stack objects of unique designs. We location a parallel gripper attached to a robotic arm higher than a basket, and a few objects in the basket — a single pink, just one green, and a person blue, for this reason the title RGB. The process is basic: stack the red item on top rated of the blue object within 20 seconds, even though the inexperienced object serves as an obstacle and distraction. The mastering course of action guarantees that the agent acquires generalised capabilities by way of training on a number of object sets. We deliberately differ the grasp and stack affordances — the traits that outline how the agent can grasp and stack just about every item. This design basic principle forces the agent to show behaviours that go over and above a straightforward decide-and-area approach.

Our RGB-Stacking benchmark consists of two task versions with distinctive levels of trouble. In “Skill Mastery,” our intention is to teach a one agent which is competent in stacking a predefined established of five triplets. In “Skill Generalisation,” we use the identical triplets for analysis, but prepare the agent on a massive set of education objects — totalling far more than a million doable triplets. To check for generalisation, these coaching objects exclude the spouse and children of objects from which the exam triplets were selected. In both of those variations, we decouple our finding out pipeline into 3 stages:
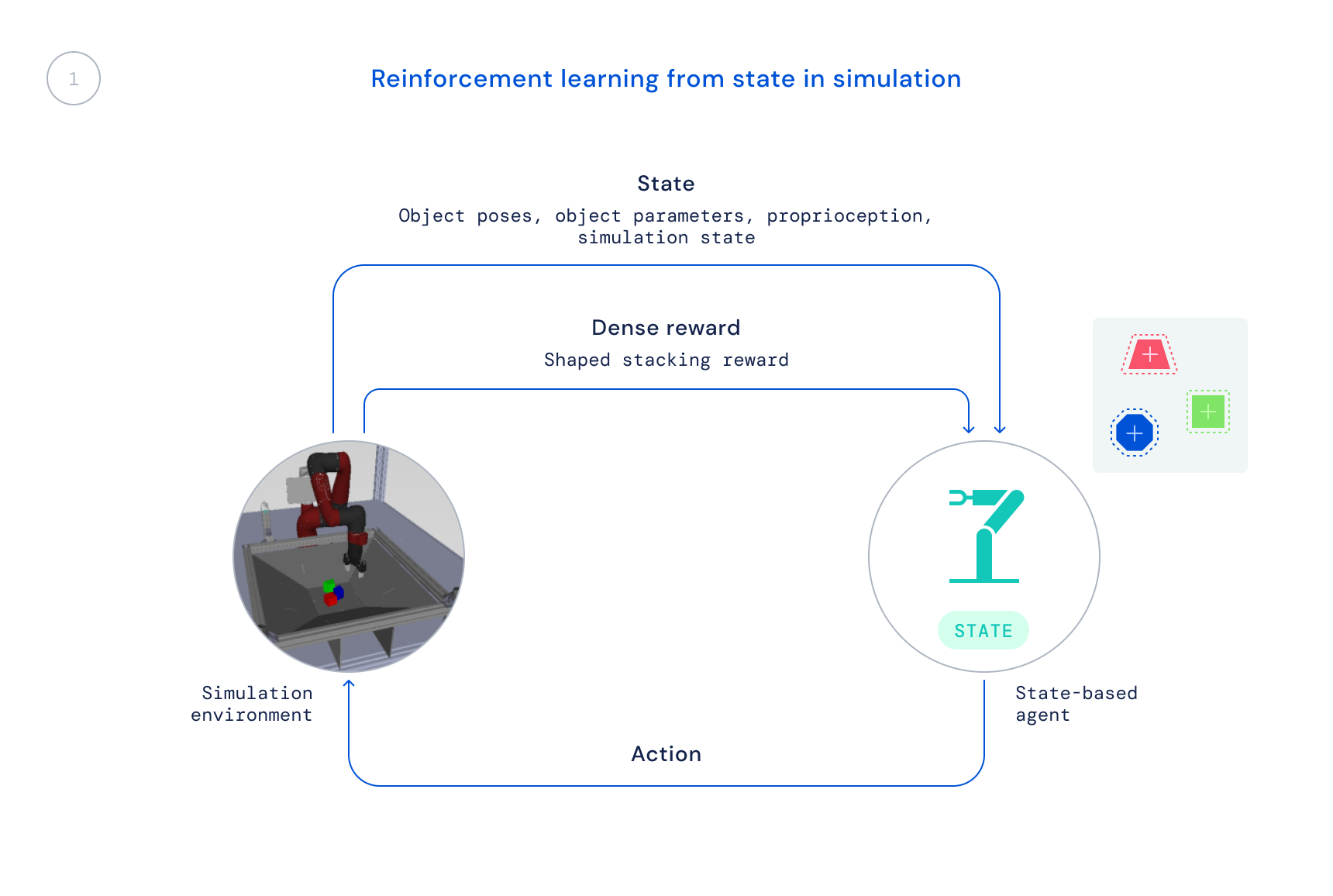
- To start with, we practice in simulation utilizing an off-the-shelf RL algorithm: Greatest a Posteriori Plan Optimisation (MPO). At this phase, we use the simulator’s state, allowing for for speedy instruction because the object positions are provided straight to the agent as a substitute of the agent needing to learn to locate the objects in visuals. The ensuing plan is not directly transferable to the real robotic considering that this facts is not accessible in the real planet.
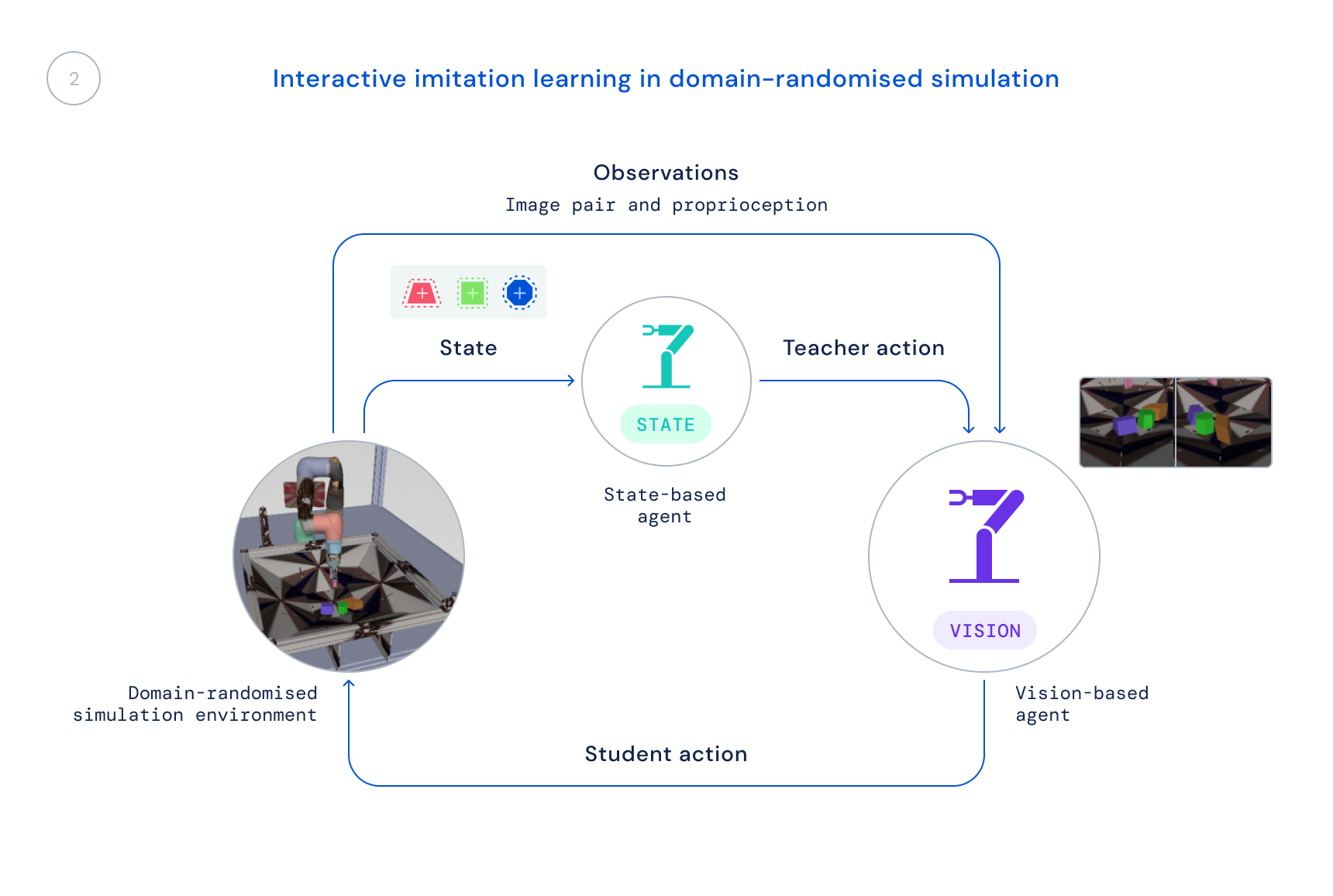
- Next, we prepare a new policy in simulation that utilizes only reasonable observations: photos and the robot’s proprioceptive condition. We use a domain-randomised simulation to boost transfer to actual-environment illustrations or photos and dynamics. The point out policy serves as a instructor, delivering the understanding agent with corrections to its behaviours, and individuals corrections are distilled into the new policy.
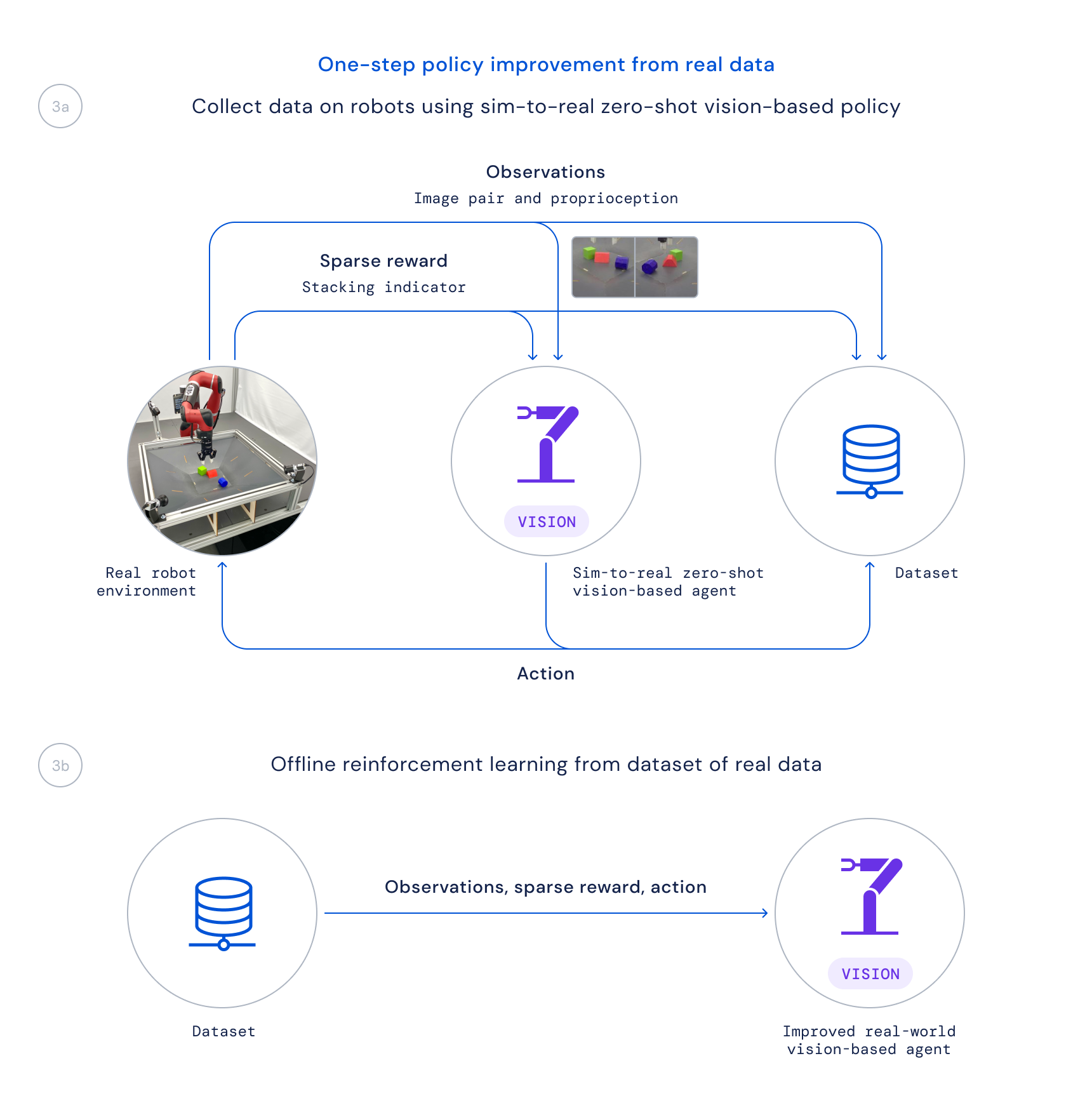
- And finally, we obtain details working with this plan on actual robots and educate an enhanced coverage from this data offline by weighting up very good transitions centered on a learned Q perform, as completed in Critic Regularised Regression (CRR). This makes it possible for us to use the details that is passively collected through the task alternatively of jogging a time-consuming on the net schooling algorithm on the true robots.
Decoupling our mastering pipeline in this sort of a way proves essential for two main good reasons. First of all, it lets us to fix the problem at all, given that it would merely consider way too prolonged if we ended up to begin from scratch on the robots right. Next, it raises our investigate velocity, due to the fact distinctive people today in our workforce can function on various components of the pipeline right before we merge these alterations for an total advancement.

In latest several years, there has been much function on making use of studying algorithms to resolving difficult real-robot manipulation difficulties at scale, but the aim of these types of work has mainly been on tasks these kinds of as greedy, pushing, or other varieties of manipulating solitary objects. The tactic to RGB-Stacking we explain in our paper, accompanied by our robotics means now readily available on GitHub, benefits in astonishing stacking approaches and mastery of stacking a subset of these objects. Still, this stage only scratches the surface area of what is doable – and the generalisation obstacle stays not absolutely solved. As researchers maintain doing work to solve the open up problem of genuine generalisation in robotics, we hope this new benchmark, along with the natural environment, types, and tools we have produced, add to new concepts and techniques that can make manipulation even less difficult and robots additional capable.
[ad_2]
Source link