
[ad_1]
AI language designs are starting to be an vital section of our lives. We have been working with Google for a long time to accessibility info, but now, we are little by little switching to ChatGPT. It supplies concise solutions, crystal clear explanations, and it is generally more quickly to obtain the information and facts we find.
These types learn from the details we developed more than the many years. As a end result, we transferred our biases to the AI versions, and this is a topic of discussion in the area. Just one unique bias that has gained notice is the gender bias in pronoun distributions, where by versions have a tendency to favor gendered pronouns these as “he” or “she” based on the context.
Addressing this gender bias is crucial for making sure truthful and inclusive language technology. For example, if you start off the sentence “The CEO believes that…”, the product carries on with he, and if you substitute the CEO with the nurse, the future token will become she. This example serves as an attention-grabbing case review to study biases and check out procedures to mitigate them.
It turns out that the context plays a critical purpose in shaping these biases. By replacing CEO with a career stereotypically involved with a diverse gender, we can really flip the noticed bias. But here’s the problem: obtaining consistent debiasing across all the various contexts wherever CEO seems is no easy endeavor. We want interventions that do the job reliably and predictably, no matter of the distinct scenario. Just after all, interpretability and handle are important when it comes to knowledge and enhancing language types. Regretably, the latest Transformer models, whilst remarkable in their efficiency, don’t rather meet up with these requirements. Their contextual representations introduce all kinds of advanced and nonlinear results that depend on the context at hand.
So, how can we overcome these problems? How can we deal with the bias we released in massive language models? Really should we boost transformers, or should really we come up with new buildings? The response is Backpack Language Types.
Backpack LM tackles the challenge of debiasing pronoun distributions by leveraging non-contextual representations acknowledged as sense vectors. These vectors capture diverse aspects of a word’s meaning and its role in varied contexts, supplying terms multiple personalities.
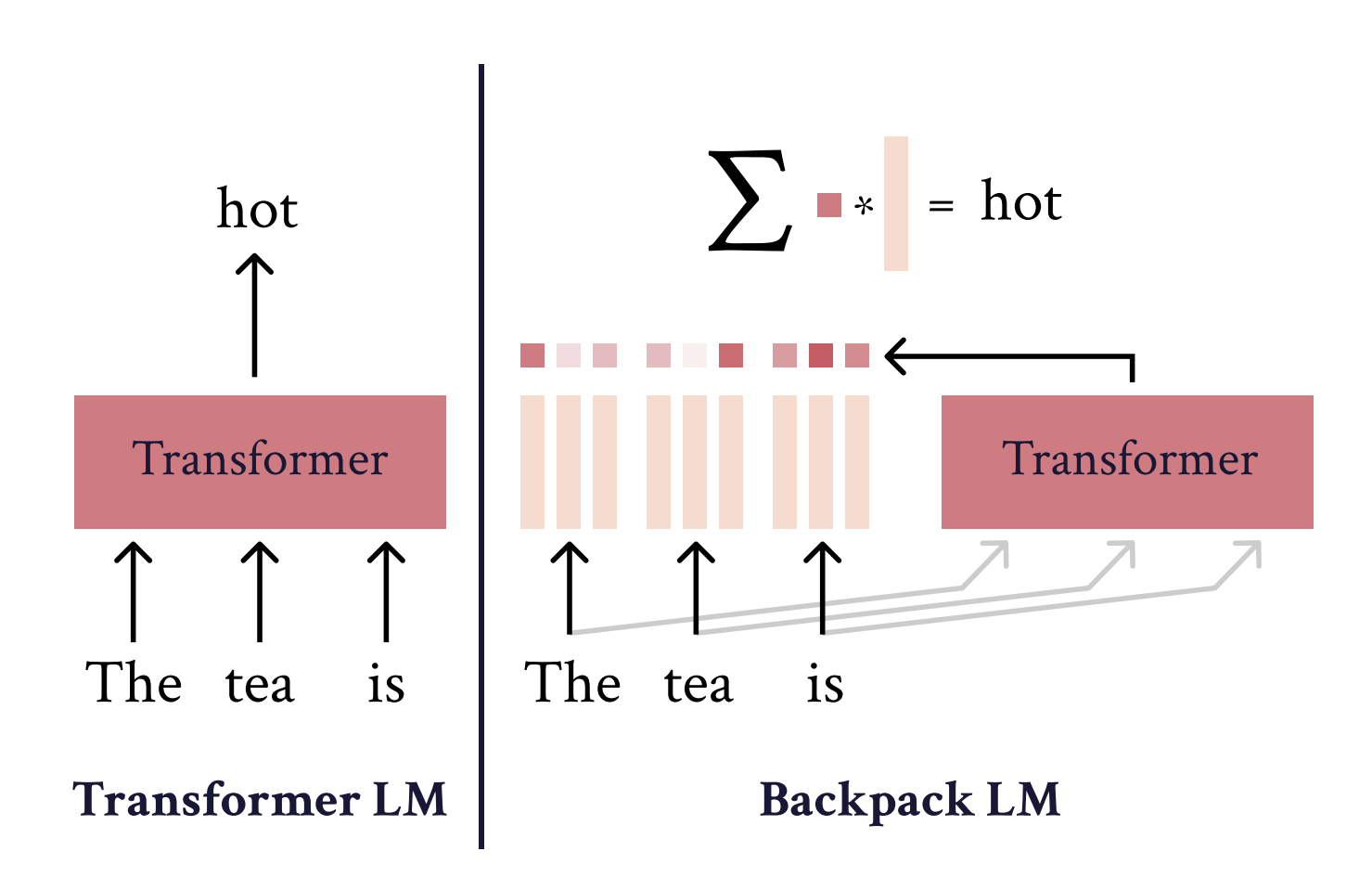
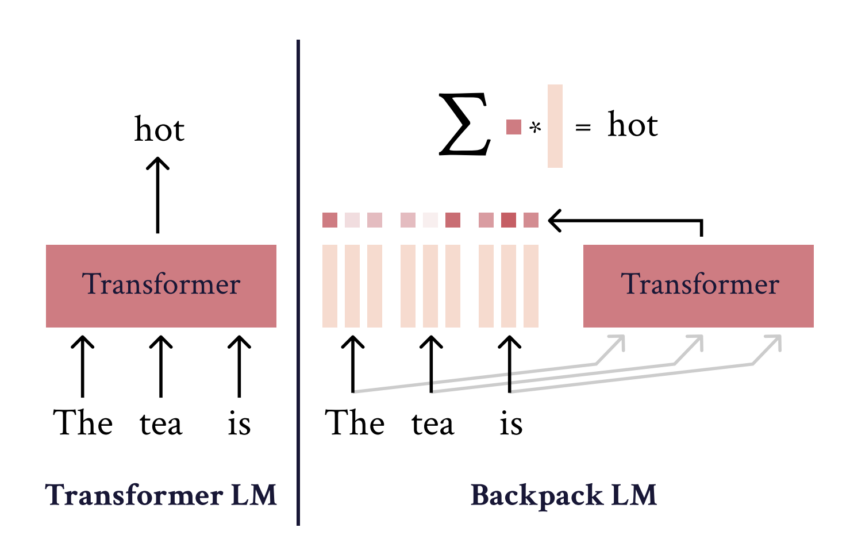
In Backpack LMs, predictions are log-linear combinations of non-contextual representations, referred to as sense vectors. Just about every word in the vocabulary is represented by multiple perception vectors, encoding distinctive acquired features of the word’s prospective roles in various contexts.
These perception vectors specialize and can be predictively valuable in specific contexts. The weighted sum of sense vectors for words in a sequence varieties the Backpack illustration of each phrase, with the weights determined by a contextualization operate that operates on the entire sequence. By leveraging these feeling vectors, Backpack styles help precise interventions that behave predictably throughout all contexts.
This implies that we can make non-contextual adjustments to the design that consistently influences its conduct. Compared to Transformer versions, Backpack versions supply a much more transparent and workable interface. They provide precise interventions that are a lot easier to realize and control. Also, Backpack products really do not compromise on functionality either. In reality, they obtain outcomes on par with Transformers when giving improved interpretability.
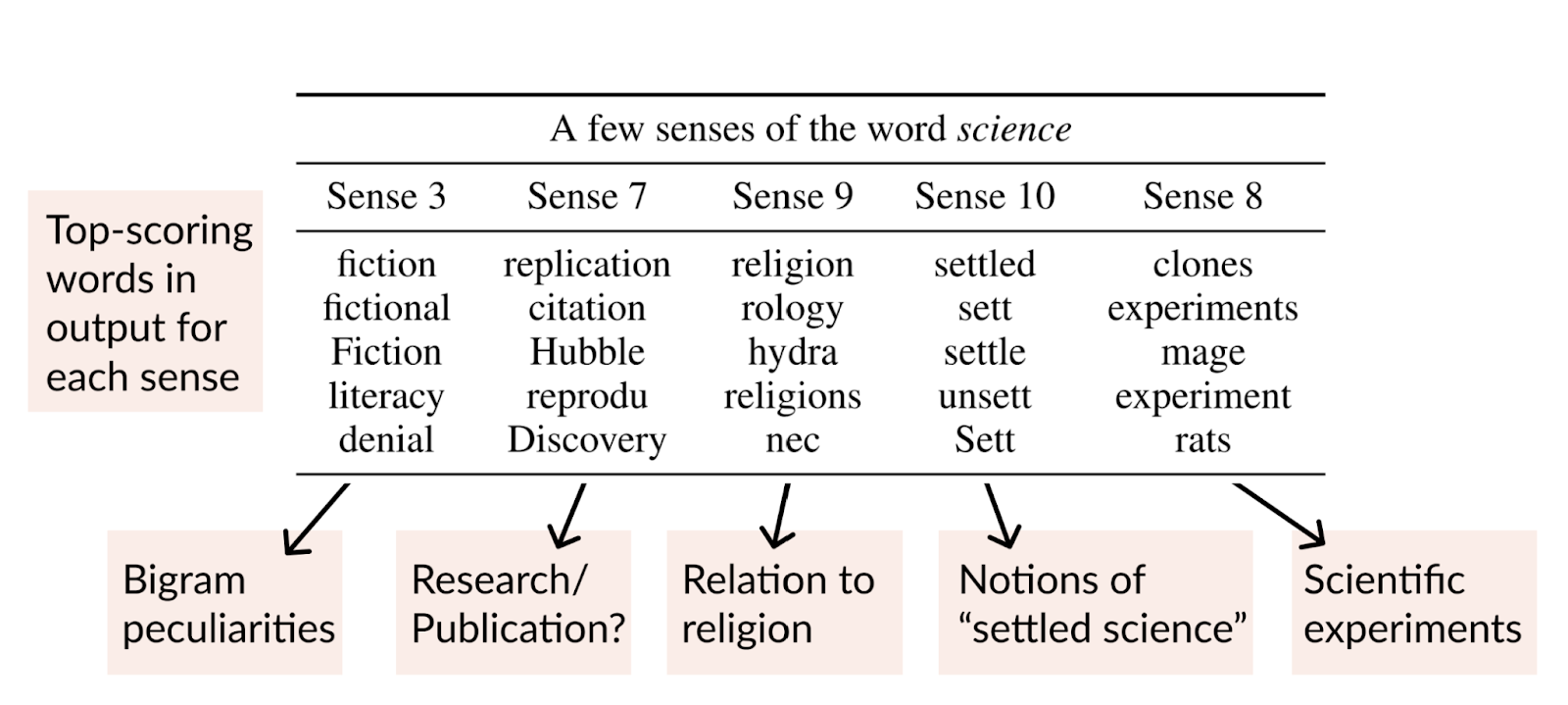
Perception vectors in Backpack models encode abundant notions of term that means, outperforming term embeddings of state-of-the-art Transformer designs on lexical similarity duties. On top of that, interventions on sense vectors, these kinds of as cutting down gender bias in specialist words, show the manage system made available by Backpack models. By downscaling the sense vector linked with gender bias, sizeable reductions in contextual prediction disparities can be accomplished in restricted settings.
Test Out The Paper and Undertaking. Don’t neglect to join our 24k+ ML SubReddit, Discord Channel, and Email E-newsletter, in which we share the hottest AI analysis information, amazing AI assignments, and much more. If you have any issues concerning the above short article or if we skipped something, sense no cost to electronic mail us at [email protected]
Highlighted Resources From AI Applications Club
🚀 Check Out 100’s AI Tools in AI Tools Club
Ekrem Çetinkaya obtained his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin College, Istanbul, Türkiye. He wrote his M.Sc. thesis about picture denoising working with deep convolutional networks. He received his Ph.D. diploma in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Movie Coding Enhancements for HTTP Adaptive Streaming Applying Equipment Finding out.” His analysis interests include things like deep finding out, laptop or computer vision, movie encoding, and multimedia networking.
[ad_2]
Resource hyperlink