
[ad_1]
In excess of the previous several years, large-scale neural networks have drawn appreciable consideration from researchers. This is mostly due to their superb effectiveness in numerous jobs, which include pure language understanding, resolving difficult mathematical equations, and even protein construction prediction. Nonetheless, in purchase to make sure that these designs make constructive contributions to culture, it is essential that they align with human values and considers human choices. The use of human opinions is a person of the most necessary elements in carrying out this mainly because it enables human beings to assess the overall performance of this sort of types primarily based on a huge selection of metrics these as precision, fairness, bias, etc., and provides insights into how these models can be enhanced to produce extra ethical outputs. In order to boost the performance of incorporating user feed-back, scientists have been experimenting with many approaches for human-in-the-loop units for the duration of the past handful of many years. Effects clearly show that ChatGPT and InstructGPT have demonstrated incredible final results as a end result of working with human opinions to learn.
These overall performance gains in language modeling have been mostly attributed to a method that depends on supervised finetuning (SFT) and Reinforcement Learning with Human Opinions (RLHF) approaches. Whilst these techniques have appreciably contributed to achieving promising results with regards to language model overall performance, they have their personal disadvantages. SFT largely depends on human annotation, rendering these types equally hard to use and inefficient in data utilization. On the other hand, considering that reinforcement understanding will work on a reward purpose foundation, it is incredibly hard to enhance these versions.
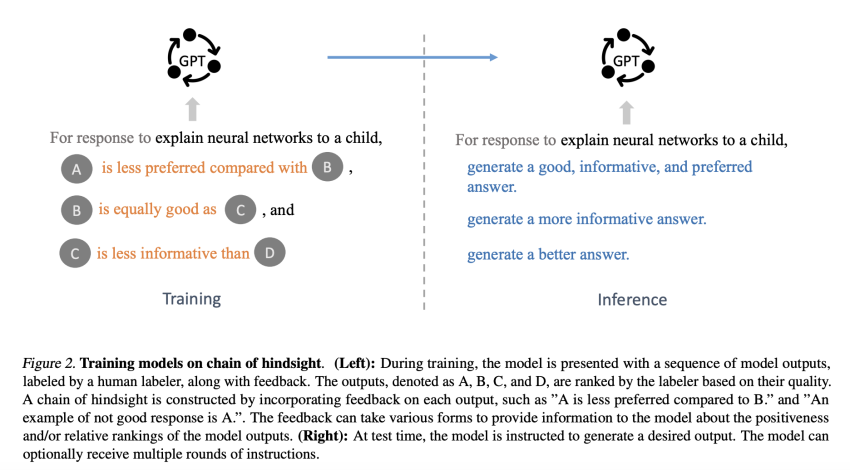
To counter these difficulties, scientists from the College of California, Berkeley, developed a novel strategy that turns all feed-back into sentences and works by using them to finetune the design to recognize the feedback. This approach, known as the Chain of Hindsight (CoH), is mostly influenced by how humans course of action considerable suggestions provided in the kind of languages. The aim of the researchers when developing the method was to combine the strengths of SFT and RLHF though avoiding employing reinforcement discovering to make use of all feedback totally. Their present-day technique takes advantage of language’s ability to realize and learn from comments, eventually improving the models’ ability to have out a huge vary of tasks far more precisely and correctly.
The researchers built use of the fact that people master nicely from prosperous opinions in the form of language. Specified the spectacular abilities of pre-educated language versions to understand correctly in context, scientists puzzled about the possibility of turning all comments into a sentence and training the styles to abide by the responses. In larger detail, the researchers proposed finetuning the product to predict final results when relying on 1 or far more sorted final results and their feedback in the sort of comparisons. CoH randomly selects 1 or far more design outputs throughout coaching and makes use of them to construct a sentence that includes both favourable and unfavorable comments in the type of comparison. For instance, two example sentences can be “The pursuing is a negative summary” and “The following summary is improved.” The design employs constructive responses at inference time to create the sought after outputs.
The CoH approach lets versions to study from both equally constructive and negative feed-back, making it possible for the identification and correction of adverse attributes or mistakes. The strategy has a variety of further positive aspects as properly. They consist of a a lot more organic and natural type of opinions and a process for training. Also, the CoH procedure significantly outperforms previously approaches in correlating language models with human tastes, according to various experimental assessments carried out by researchers. The approach is chosen in human evaluations and performed remarkably perfectly on summarization and dialogue responsibilities. The UC Berkeley staff strongly believes that CoH has monumental probable for use in the upcoming with various other kinds of comments, such as automatic and numeric feedback.
Test out the Paper and Task. All Credit history For This Analysis Goes To the Scientists on This Venture. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and E mail Publication, the place we share the most recent AI study news, awesome AI tasks, and additional.
Khushboo Gupta is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Technological innovation(IIT), Goa. She is passionate about the fields of Machine Understanding, Natural Language Processing and Website Enhancement. She enjoys studying additional about the technical subject by participating in numerous difficulties.
[ad_2]
Resource url