
[ad_1]
Pre-teaching visual language (VL) types on world wide web-scale picture-caption datasets has recently emerged as a potent alternate to common pre-education on picture classification information. Graphic-caption datasets are thought of to be far more “open-domain” because they contain broader scene types and vocabulary phrases, which consequence in versions with powerful overall performance in couple of- and zero-shot recognition responsibilities. However, illustrations or photos with great-grained course descriptions can be uncommon, and the course distribution can be imbalanced since impression-caption datasets do not go as a result of manual curation. By contrast, huge-scale classification datasets, this kind of as ImageNet, are frequently curated and can consequently give good-grained groups with a balanced label distribution. While it may seem promising, straight combining caption and classification datasets for pre-coaching is often unsuccessful as it can consequence in biased representations that do not generalize well to several downstream tasks.
In “Prefix Conditioning Unifies Language and Label Supervision”, offered at CVPR 2023, we demonstrate a pre-coaching approach that takes advantage of the two classification and caption datasets to give complementary positive aspects. Initially, we display that naïvely unifying the datasets benefits in sub-optimal efficiency on downstream zero-shot recognition tasks as the design is influenced by dataset bias: the coverage of graphic domains and vocabulary terms is diverse in every single dataset. We deal with this dilemma throughout training by means of prefix conditioning, a novel easy and successful system that uses prefix tokens to disentangle dataset biases from visible principles. This approach makes it possible for the language encoder to discover from both equally datasets when also tailoring function extraction to every dataset. Prefix conditioning is a generic process that can be quickly integrated into present VL pre-education goals, these kinds of as Contrastive Language-Picture Pre-coaching (CLIP) or Unified Contrastive Understanding (UniCL).
Superior-level strategy
We notice that classification datasets are inclined to be biased in at least two methods: (1) the images mostly incorporate solitary objects from restricted domains, and (2) the vocabulary is limited and lacks the linguistic overall flexibility needed for zero-shot discovering. For example, the course embedding of “a image of a dog” optimized for ImageNet generally results in a photo of a single dog in the middle of the image pulled from the ImageNet dataset, which does not generalize perfectly to other datasets containing illustrations or photos of various canines in distinctive spatial spots or a pet dog with other subjects.
By contrast, caption datasets have a wider variety of scene forms and vocabularies. As revealed underneath, if a model only learns from two datasets, the language embedding can entangle the bias from the graphic classification and caption dataset, which can minimize the generalization in zero-shot classification. If we can disentangle the bias from two datasets, we can use language embeddings that are tailor-made for the caption dataset to enhance generalization.
 |
| Top rated: Language embedding entangling the bias from image classification and caption dataset. Base: Language embeddings disentangles the bias from two datasets. |
Prefix conditioning
Prefix conditioning is partially motivated by prompt tuning, which prepends learnable tokens to the enter token sequences to instruct a pre-trained model backbone to discover task-distinct awareness that can be utilized to clear up downstream responsibilities. The prefix conditioning solution differs from prompt tuning in two methods: (1) it is designed to unify picture-caption and classification datasets by disentangling the dataset bias, and (2) it is utilized to VL pre-education whilst the typical prompt tuning is applied to wonderful-tune products. Prefix conditioning is an express way to specifically steer the conduct of design backbones centered on the sort of datasets offered by customers. This is especially handy in manufacturing when the amount of diverse kinds of datasets is recognized ahead of time.
During education, prefix conditioning learns a textual content token (prefix token) for each individual dataset variety, which absorbs the bias of the dataset and will allow the remaining text tokens to aim on mastering visual ideas. Precisely, it prepends prefix tokens for each and every dataset style to the input tokens that advise the language and visible encoder of the enter knowledge form (e.g., classification vs. caption). Prefix tokens are experienced to discover the dataset-sort-distinct bias, which permits us to disentangle that bias in language representations and make use of the embedding uncovered on the impression-caption dataset through check time, even without having an enter caption.
We employ prefix conditioning for CLIP working with a language and visible encoder. All through examination time, we make use of the prefix utilized for the impression-caption dataset given that the dataset is intended to protect broader scene varieties and vocabulary text, main to much better overall performance in zero-shot recognition.
 |
| Illustration of the Prefix Conditioning. |
Experimental results
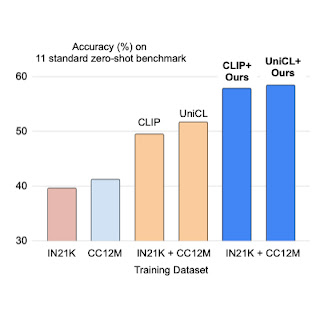
We utilize prefix conditioning to two forms of contrastive loss, CLIP and UniCL, and appraise their functionality on zero-shot recognition jobs when compared to styles qualified with ImageNet21K (IN21K) and Conceptual 12M (CC12M). CLIP and UniCL versions experienced with two datasets making use of prefix conditioning display substantial enhancements in zero-shot classification accuracy.
 |
| Zero-shot classification precision of designs experienced with only IN21K or CC12M compared to CLIP and UniCL versions trained with both equally two datasets employing prefix conditioning (“Ours”). |
Research on examination-time prefix
The table under describes the efficiency transform by the prefix applied all through examination time. We demonstrate that by applying the same prefix utilised for the classification dataset (“Prompt”), the overall performance on the classification dataset (IN-1K) improves. When utilizing the same prefix utilised for the impression-caption dataset (“Caption”), the general performance on other datasets (Zero-shot AVG) enhances. This examination illustrates that if the prefix is tailor-made for the picture-caption dataset, it achieves much better generalization of scene styles and vocabulary text.
 |
| Evaluation of the prefix used for test-time. |
Analyze on robustness to graphic distribution shift
We study the change in image distribution employing ImageNet variants. We see that the “Caption” prefix performs better than “Prompt” in ImageNet-R (IN-R) and ImageNet-Sketch (IN-S), but underperforms in ImageNet-V2 (IN-V2). This signifies that the “Caption” prefix achieves generalization on domains significantly from the classification dataset. Thus, the exceptional prefix in all probability differs by how much the check domain is from the classification dataset.
 |
| Examination on the robustness to impression-degree distribution change. IN: ImageNet, IN-V2: ImageNet-V2, IN-R: Artwork, Cartoon style ImageNet, IN-S: ImageNet Sketch. |
Conclusion and long run do the job
We introduce prefix conditioning, a procedure for unifying image caption and classification datasets for much better zero-shot classification. We display that this solution prospects to better zero-shot classification accuracy and that the prefix can regulate the bias in the language embedding. One particular limitation is that the prefix realized on the caption dataset is not always ideal for the zero-shot classification. Determining the optimal prefix for each and every take a look at dataset is an attention-grabbing route for upcoming get the job done.
Acknowledgements
This investigation was carried out by Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Many thanks to Zizhao Zhang and Sergey Ioffe for their important comments.
[ad_2]
Supply hyperlink