
[ad_1]
Textual content-to-Graphic era styles are lately revolutionizing Artificial Intelligence (AI) and the way innovative image synthesis is executed. They use powerful language types to understand textual content enter prompts and change them into workable multidimensional structures known as tokens, which incorporate all the essential facts contained in the presented text.
Huge textual content models like CLIP use these tokens with a contrastive learning objective for cross-modal retrieval duties, which involve obtaining semantically relevant matches between text and photos. CLIP exploits extensive impression-textual content pairs datasets to master the associations involving graphic and text captions. Nicely-proven diffusion styles, these kinds of as Stable Diffusion, DALL-E, or Midjourney, use CLIP for semantic awareness in the diffusion procedure, which is the sequence of joint methods of incorporating sounds to an impression and denoising it to recuperate a far more specific visualization.
From these complicated versions, easier but nonetheless powerful alternatives can be derived through Rating Distillation Samples (SDS). SDS includes teaching a more compact design to forecast the scores (or log chances) assigned to photos by a much larger pre-trained model, which functions as a guidebook for the estimation system.
Even though extremely impressive and powerful in simplifying advanced diffusion models, SDS suffers from synthesis artifacts. Just one of the principal problems connected with SDS is method collapse, which describes its tendency to converge towards distinct modes. This often leads to the output of blurry outputs, only capturing the features explicitly explained in the prompt, like in Figure 2.
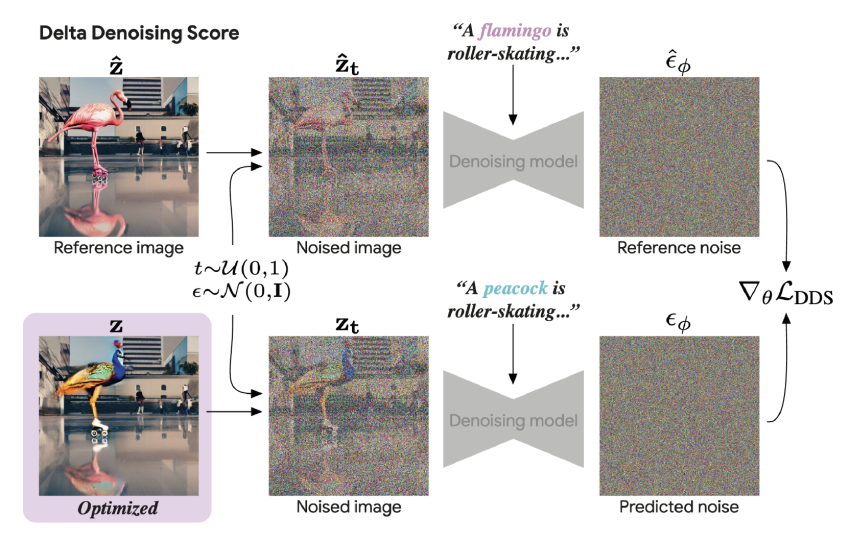
In this optic, a new facts distillation system, termed Delta Distillation Score (DDS), has been proposed. This technique’s name will come from the way the distillation score is computed. Contrary to SDS, which queries the generative design with an picture-textual content pair, DDS utilizes an supplemental question of a reference pair, the place the text matches the image’s written content.
The score constitutes the change, or delta, between the outcomes of the two queries.
The essential kind of DDS requires two impression-text pairs, a person is the reference and does not adjust for the duration of the optimization, and the other represents the optimization target, which should match the goal text prompt. DDS potential customers to helpful gradients, which contemplate the edited places of the image although leaving the other people untouched.
In DDS, the resource graphic and its text captions assistance estimate undesirable and noisy gradient instructions launched by SDS. In fantastic-grained or partial enhancing of the impression applying a new text description, the reference estimation helps get a cleaner gradient course to update the picture.
What’s more, DDS can modify visuals by transforming their textual descriptions devoid of requiring a visible mask to be computed or furnished. Also, it enables the coaching of an impression-to-image model without the need of the want for paired schooling data, which final results in a zero-shot impression translation technique. According to the authors, this zero-shot training procedure can be used for one and multi-endeavor graphic translation. Also, the supply distribution can include things like the two reliable and synthetically generated images.
An image is documented down below to compare the efficiency distinction in between DDS and condition-of-the-art techniques for impression-to-graphic translation.

This was a summary of Delta Denoising Score, a novel AI method to present faithful, thoroughly clean, and detailed impression-to-graphic and textual content-to-graphic synthesis. If you are interested, you can learn additional about this system in the hyperlinks underneath.
Test out the Paper and Venture Web page. Do not overlook to join our 20k+ ML SubReddit, Discord Channel, and E mail Publication, the place we share the latest AI study information, awesome AI initiatives, and extra. If you have any thoughts concerning the earlier mentioned article or if we skipped everything, experience totally free to email us at [email protected]
🚀 Examine Out 100’s AI Applications in AI Applications Club
Daniele Lorenzi acquired his M.Sc. in ICT for World wide web and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. applicant at the Institute of Info Engineering (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is at this time doing the job in the Christian Doppler Laboratory ATHENA and his investigation interests include things like adaptive video clip streaming, immersive media, device discovering, and QoS/QoE evaluation.
[ad_2]
Source url