

[ad_1]
In new years, synthetic intelligence agents have succeeded in a vary of intricate sport environments. For instance, AlphaZero defeat world-winner systems in chess, shogi, and Go following starting out with recognizing no extra than the fundamental rules of how to play. By way of reinforcement finding out (RL), this one process learnt by participating in spherical following round of online games as a result of a repetitive system of demo and error. But AlphaZero nonetheless qualified independently on every activity — unable to basically learn another recreation or activity without the need of repeating the RL system from scratch. The exact same is accurate for other successes of RL, these as Atari, Seize the Flag, StarCraft II, Dota 2, and Cover-and-Search for. DeepMind’s mission of solving intelligence to advance science and humanity led us to investigate how we could get over this limitation to create AI agents with extra typical and adaptive behaviour. Instead of studying a single sport at a time, these agents would be capable to respond to wholly new disorders and enjoy a complete universe of games and duties, like kinds in no way noticed before.
These days, we posted “Open up-Finished Mastering Leads to Commonly Able Brokers,” a preprint detailing our initially actions to coach an agent capable of participating in several distinctive online games without the need of needing human conversation data. We established a vast video game atmosphere we call XLand, which involves a lot of multiplayer game titles within just dependable, human-relatable 3D worlds. This ecosystem can make it feasible to formulate new studying algorithms, which dynamically control how an agent trains and the games on which it trains. The agent’s abilities boost iteratively as a response to the worries that come up in schooling, with the studying method frequently refining the teaching jobs so the agent under no circumstances stops learning. The outcome is an agent with the potential to triumph at a huge spectrum of responsibilities — from uncomplicated item-getting challenges to intricate video games like hide and seek out and seize the flag, which were being not encountered during education. We uncover the agent displays typical, heuristic behaviours this kind of as experimentation, behaviours that are widely relevant to quite a few jobs somewhat than specialised to an individual undertaking. This new solution marks an critical action toward building additional basic agents with the flexibility to adapt promptly inside continuously transforming environments.
A universe of schooling jobs
A deficiency of training knowledge — the place “data” factors are distinct responsibilities — has been a person of the key components limiting RL-skilled agents’ conduct currently being standard sufficient to apply across video games. Without getting ready to teach brokers on a huge more than enough established of jobs, brokers trained with RL have been unable to adapt their learnt behaviours to new tasks. But by designing a simulated place to allow for for procedurally generated jobs, our crew produced a way to train on, and generate experience from, responsibilities that are made programmatically. This enables us to include billions of tasks in XLand, across different video games, worlds, and players.
Our AI agents inhabit 3D initially-particular person avatars in a multiplayer ecosystem intended to simulate the physical planet. The players perception their environment by observing RGB photos and receive a textual content description of their purpose, and they teach on a assortment of video games. These online games are as straightforward as cooperative game titles to obtain objects and navigate worlds, where by the purpose for a participant could be “be in close proximity to the purple cube.” More advanced games can be dependent on picking out from many gratifying choices, this sort of as “be in the vicinity of the purple cube or place the yellow sphere on the pink flooring,” and much more aggressive game titles include actively playing towards co-gamers, these as symmetric disguise and request exactly where each player has the goal, “see the opponent and make the opponent not see me.” Every single video game defines the rewards for the gamers, and each individual player’s supreme goal is to maximise the benefits.
Because XLand can be programmatically specified, the activity house makes it possible for for knowledge to be generated in an automated and algorithmic style. And mainly because the responsibilities in XLand entail various gamers, the conduct of co-gamers greatly influences the troubles confronted by the AI agent. These intricate, non-linear interactions develop an suitable supply of data to educate on, given that at times even tiny modifications in the factors of the ecosystem can consequence in substantial modifications in the troubles for the agents.

Teaching solutions
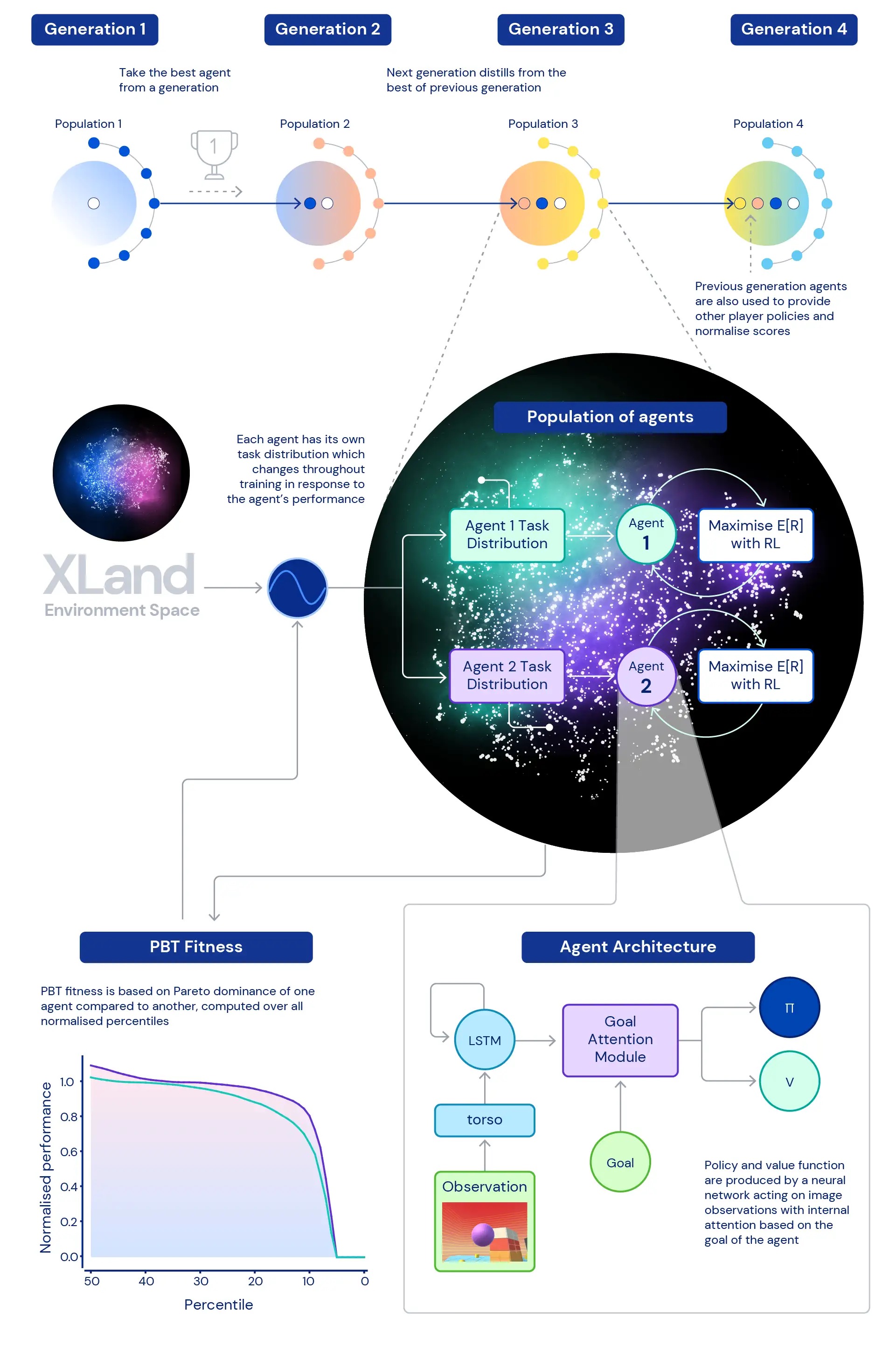
Central to our research is the job of deep RL in coaching the neural networks of our agents. The neural community architecture we use presents an attention mechanism about the agent’s internal recurrent point out — supporting guide the agent’s notice with estimates of subgoals one of a kind to the video game the agent is taking part in. We have identified this purpose-attentive agent (GOAT) learns a lot more normally able insurance policies.
We also explored the problem, what distribution of education responsibilities will create the very best possible agent, specially in this sort of a vast setting? The dynamic process generation we use will allow for continuous adjustments to the distribution of the agent’s schooling duties: just about every process is produced to be neither way too hard nor far too easy, but just ideal for schooling. We then use inhabitants based training (PBT) to change the parameters of the dynamic endeavor generation centered on a physical fitness that aims to enhance agents’ common ability. And finally we chain jointly numerous training runs so every technology of brokers can bootstrap off the earlier era.
This leads to a last instruction method with deep RL at the main updating the neural networks of agents with each individual stage of expertise:
- the ways of encounter come from instruction duties that are dynamically generated in response to agents’ behaviour,
- agents’ task-creating features mutate in reaction to agents’ relative general performance and robustness,
- at the outermost loop, the generations of brokers bootstrap from every other, give at any time richer co-players to the multiplayer environment, and redefine the measurement of progression by itself.
The instruction process starts off from scratch and iteratively builds complexity, continually transforming the mastering issue to keep the agent discovering. The iterative mother nature of the put together mastering technique, which does not optimise a bounded functionality metric but relatively the iteratively described spectrum of general capacity, prospects to a likely open up-finished mastering process for agents, constrained only by the expressivity of the atmosphere room and agent neural network.
Measuring development
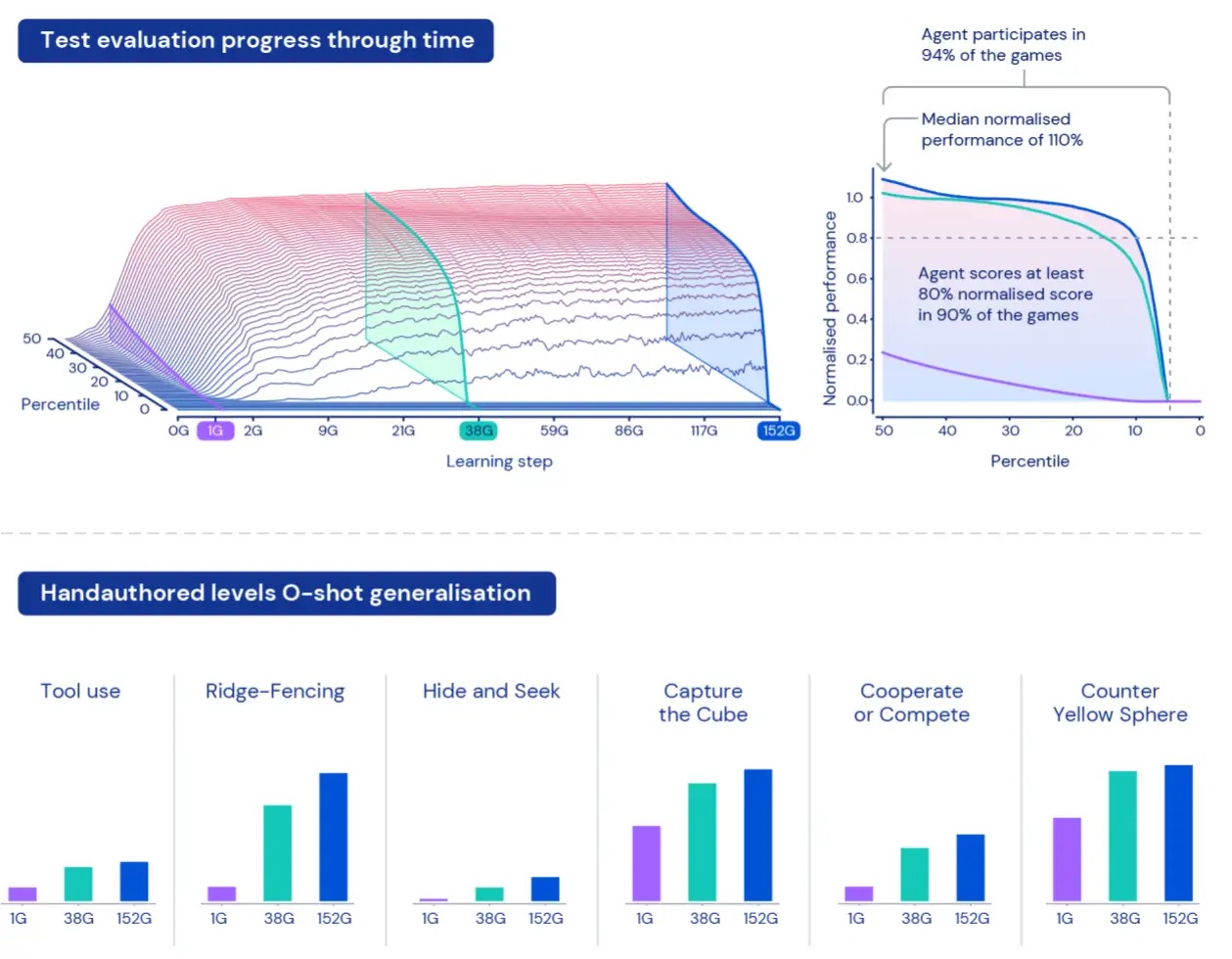
To evaluate how brokers execute inside of this broad universe, we generate a set of evaluation duties making use of video games and worlds that stay independent from the info applied for coaching. These “held-out” responsibilities involve especially human-intended responsibilities like disguise and search for and capture the flag.
Mainly because of the size of XLand, understanding and characterising the effectiveness of our brokers can be a obstacle. Each individual activity consists of diverse degrees of complexity, diverse scales of achievable rewards, and distinctive capabilities of the agent, so merely averaging the reward in excess of held out tasks would hide the real differences in complexity and rewards — and would effectively deal with all jobs as similarly interesting, which is not necessarily true of procedurally generated environments.
To triumph over these constraints, we acquire a various tactic. For starters, we normalise scores for every task making use of the Nash equilibrium value computed employing our current set of experienced gamers. Secondly, we take into account the overall distribution of normalised scores — fairly than hunting at average normalised scores, we glance at the diverse percentiles of normalised scores — as properly as the share of responsibilities in which the agent scores at least just one phase of reward: participation. This signifies an agent is regarded as far better than yet another agent only if it exceeds efficiency on all percentiles. This method to measurement offers us a significant way to assess our agents’ functionality and robustness.
Far more typically able agents
Just after coaching our brokers for five generations, we observed constant improvements in understanding and effectiveness across our held-out analysis room. Playing approximately 700,000 exceptional video games in 4,000 special worlds inside of XLand, every agent in the final generation professional 200 billion schooling actions as a outcome of 3.4 million exceptional responsibilities. At this time, our brokers have been able to participate in just about every procedurally produced evaluation undertaking except for a handful that were being unattainable even for a human. And the effects we’re seeing plainly show common, zero-shot conduct throughout the job house — with the frontier of normalised rating percentiles continuously improving.
Seeking qualitatively at our brokers, we generally see common, heuristic behaviours arise — fairly than remarkably optimised, particular behaviours for person tasks. Rather of agents knowing specifically the “best thing” to do in a new predicament, we see evidence of agents experimenting and shifting the state of the planet until they’ve attained a worthwhile state. We also see brokers depend on the use of other applications, like objects to occlude visibility, to build ramps, and to retrieve other objects. Because the atmosphere is multiplayer, we can look at the progression of agent behaviours though instruction on held-out social dilemmas, this sort of as in a game of “chicken”. As teaching progresses, our agents show up to show more cooperative behaviour when playing with a copy of by themselves. Presented the nature of the surroundings, it is challenging to pinpoint intentionality — the behaviours we see normally show up to be accidental, but still we see them occur continually.
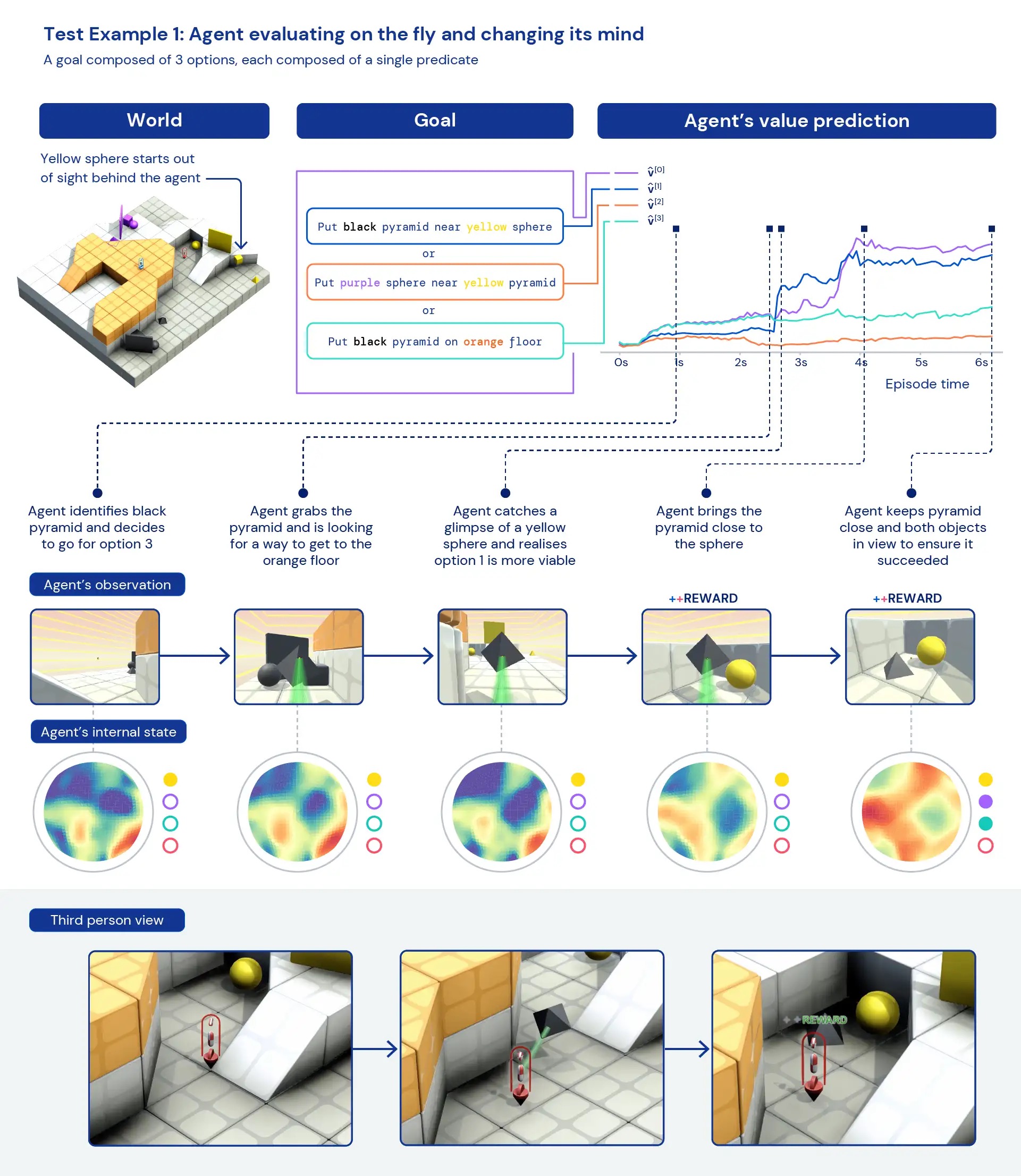
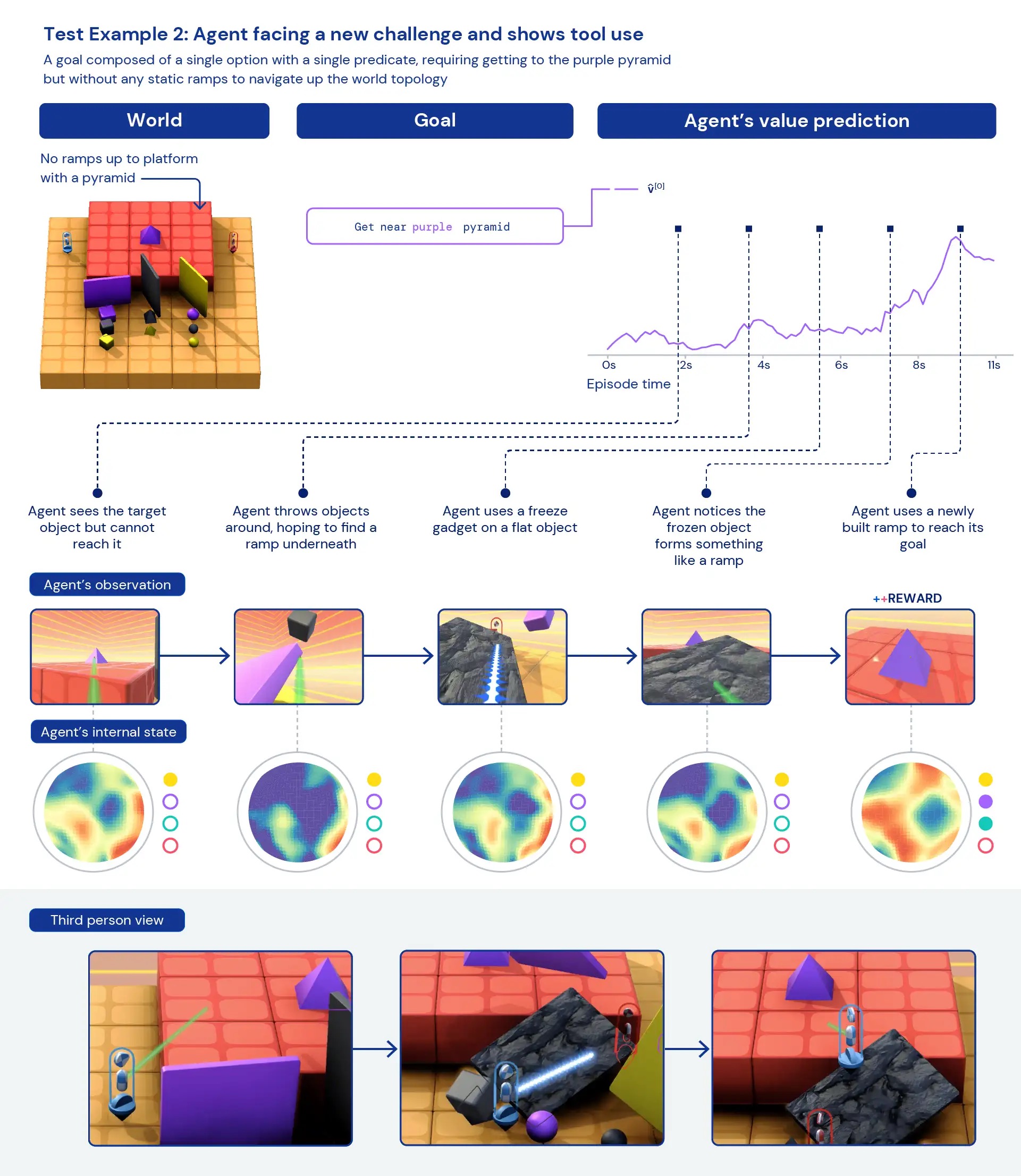
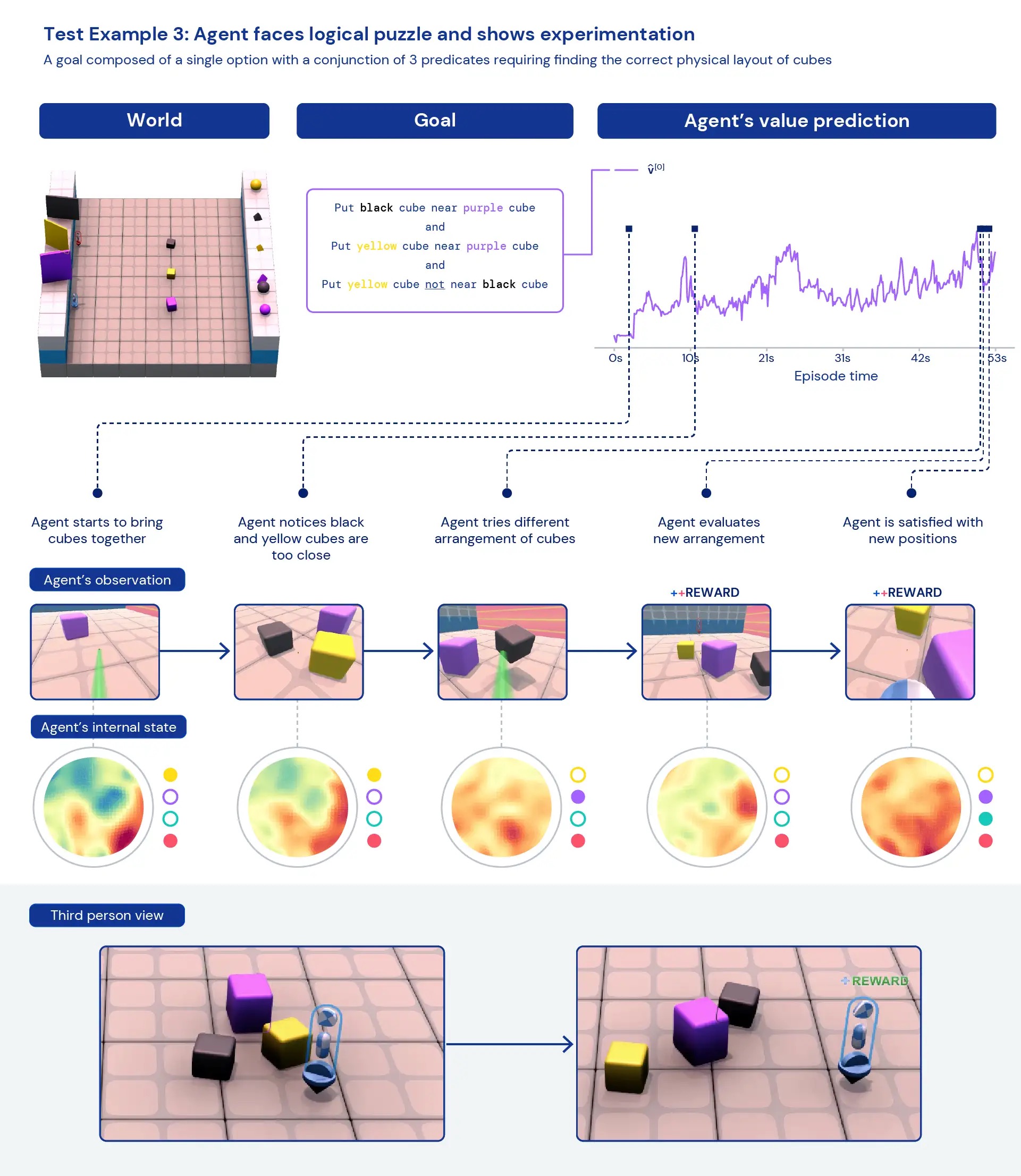



Analysing the agent’s inner representations, we can say that by having this approach to reinforcement studying in a huge task house, our brokers are knowledgeable of the basics of their bodies and the passage of time and that they recognize the significant-degree composition of the game titles they come across. Probably even extra curiously, they obviously recognise the reward states of their setting. This generality and variety of behaviour in new jobs hints toward the likely to fine-tune these agents on downstream responsibilities. For instance, we show in the complex paper that with just 30 minutes of concentrated coaching on a recently introduced intricate task, the brokers can swiftly adapt, whereas agents qualified with RL from scratch can’t master these responsibilities at all.
By acquiring an surroundings like XLand and new teaching algorithms that assistance the open-finished development of complexity, we have seen obvious symptoms of zero-shot generalisation from RL agents. While these agents are starting off to be typically able in this activity space, we search forward to continuing our investigate and enhancement to further strengthen their effectiveness and make at any time additional adaptive brokers.
For much more particulars, see the preprint of our specialized paper — and films of the benefits we have seen. We hope this could aid other scientists also see a new route towards producing a lot more adaptive, normally capable AI brokers. If you’re psyched by these advancements, take into account becoming a member of our staff.
[ad_2]
Source backlink